Summaries for several ECCV 2020 papers
目录:
- Summaries for several ECCV 2020 papers
- Deep Hough Transform for Semantic Line Detection
- PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
- Learning Stereo from Single Images
- Attentive Normalization
- TIDE: A General Toolbox for Identifying Object Detection Errors
- Arbitrary-Oriented Object Detection with Circular Smooth Label
- RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
Deep Hough Transform for Semantic Line Detection
本文的主要贡献:
- DHT 操作,对整个feature map操作,作者提供了cuda 加速的code.将直线特征转换为点特征
- 提出EA score 替代IoU用于评价直线的detection. (Segmentation的IoU对直线特征的评价比较粗糙)
与Segmentation检测直线的区别:
- 只能给出线的方程,若需要检测的是线段,本文给出的方案似乎没有办法处理.
整体推理结构

DHT 运算示意图
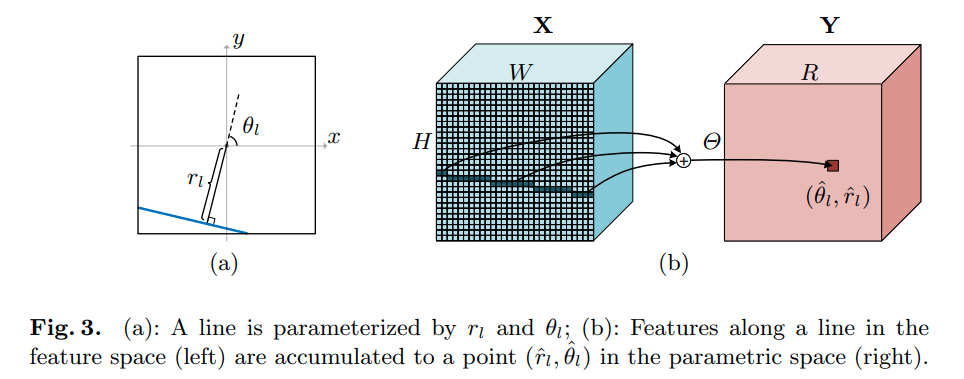
EA Score Euclidean distance and Angular distance
角度距离,基于与水平方向的夹角的差:
欧氏距离,基于直线在图上的中点的 normalized 距离 (先将图片归一化为一个单位方块)
EA Score:
PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
本文的主要贡献是提出了PIoU (pixel IoU) Loss,一个基于IoU的,针对旋转bounding box (OBB)的, 可微分的,更高效率的损失函数
- 与Rotated IoU Loss相比,运算速度更快
- 与目前更常用的L1 Loss相比,回归旋转 bounding box的性能更好,也与最终评判指标IoU更相近。
- 提供了piou的cuda加速代码
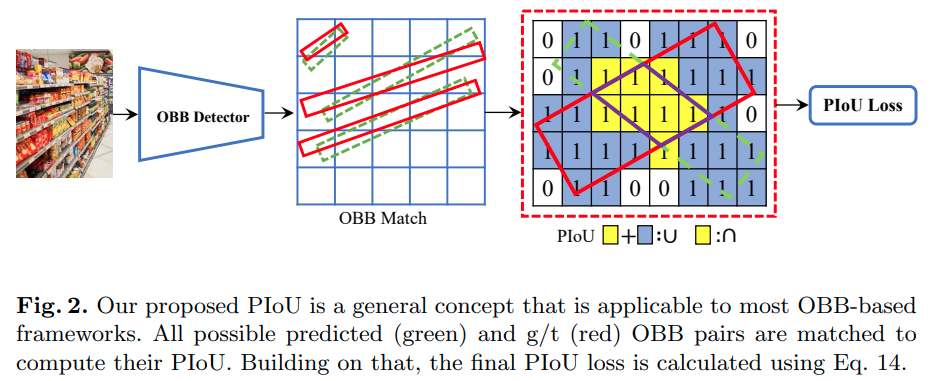
结合上图,本文的发展思路:
- PIoU 实质相当于数出两个旋转bounding box相交部分有多少个pixel,结合box的大小可以得到pixel 上的IoU.
- 如何快速地判断一个pixel是否在bounding box内? piou算法
- 判断操作是不可导的,如何软化(soften)这个判断操作使得PIoU 对预测框的中心点位置,长宽,转角可导?
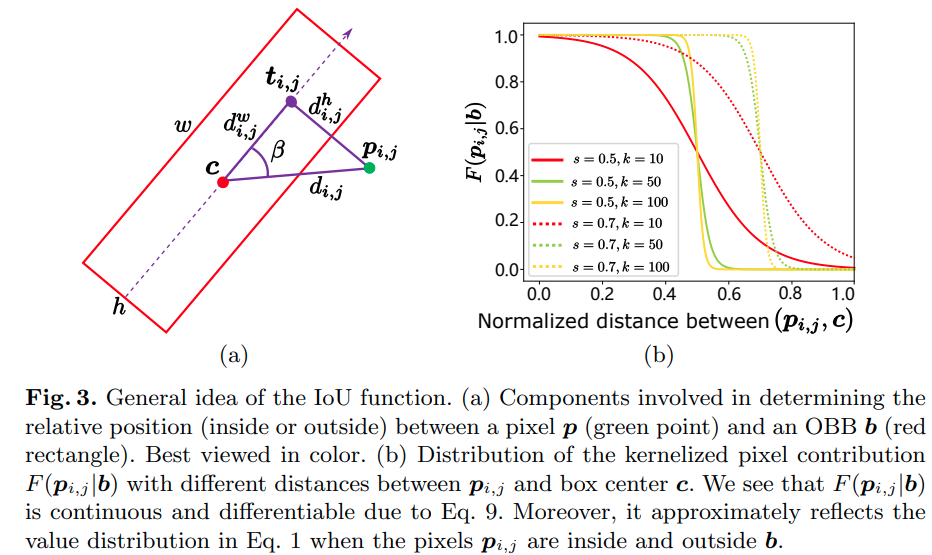
由 (a)可知判断算法为:
使用一个 的函数软化这个逻辑判断.
Learning Stereo from Single Images
这篇paper做了一个比较神奇的任务,也就是从单目图片生成双目训练集
简单来说就是 单目图片 RGBD图片 视差图 双目数据。 作者使用这样生成的双目作为训练数据得到了相当好的双目匹配性能。
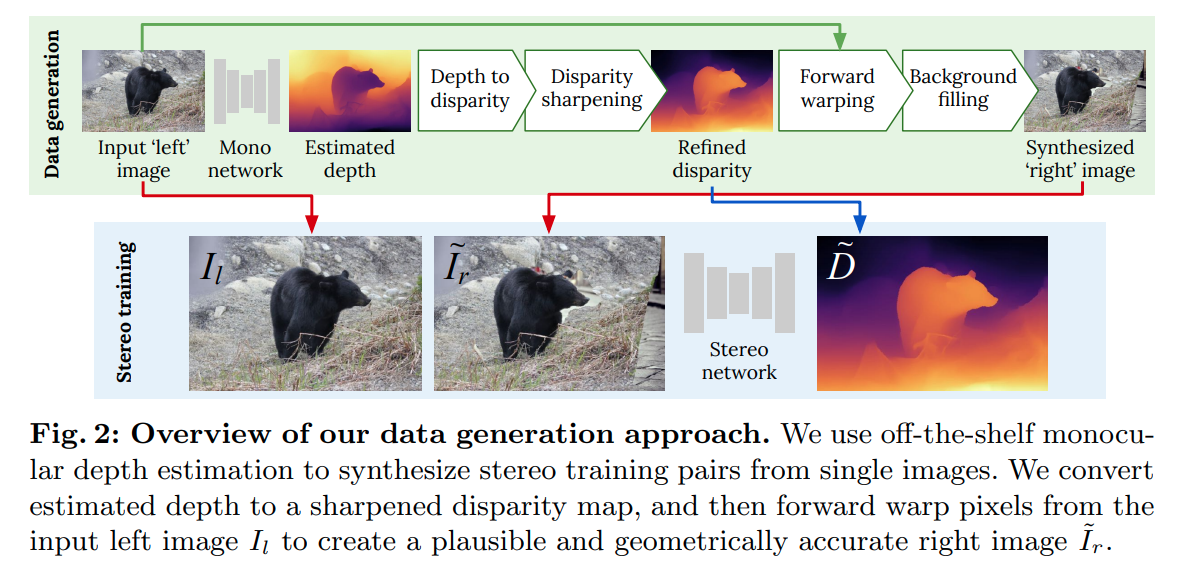
核心新的内容在与 disparity sharpening还有forward warping这两步
Occlusion and Collisions Aware Forward Warping
直接地采样会导致两个问题,一个是因为遮挡产生的孔(新视角可观察,旧视角不可观察的内容),一个是碰撞(旧视角可观察,新视角与其他像素重合)
多个像素对应一个像素(碰撞)时,选取保留视差较大的点.
对于空白的区域,本文提出从数据库中随机选取另一张图,使用color transfer算法将的颜色风格转换为的。然后填补上空白的部分.填补的方式按照Cut, Paste and Learn.
color transfer的做法是将RGB图片转变为CIE Lab格式,将Source 图各个Channel的均值与方差转换为Target 图的即可。
Cut, Paste and Learn的在填补的时候使用的是 Gaussian以及Poisson Blending. 其中Poisson Blending, 是将填补过程理解为一个带有狄利克雷边界条件的泊松偏微分方程,这个做法的intuition以及证明可以在一个lecture ppt中找到.
Depth Sharpening
作者也指出了单目深度估计很容易在物体的边缘生成过渡形态的点,和CDN指出的现象相同。本文作者的思路则是对于 Sobel edge filter相应大于三的点标记为"flying pixels",将其disparity赋值为离它最近的"non-flying" pixel.
Attentive Normalization
这篇paper提出了一个Normalization + SE的融合
class hsigmoid(nn.Module):
""" Hard Linear Sigmoid
"""
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
class AttentionWeights(nn.Module):
def __init__(self, num_channels, k, attention_mode=0):
super(AttentionWeights, self).__init__()
self.k = k
self.avgpool = nn.AdaptiveAvgPool2d(1)
layers = []
if attention_mode == 0:
layers = [ nn.Conv2d(num_channels, k, 1),
hsigmoid() ]
elif attention_mode == 2:
layers = [ nn.Conv2d(num_channels, k, 1, bias=False),
hsigmoid() ]
else:
raise NotImplementedError("Unknow attention weight type")
self.attention = nn.Sequential(*layers)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x)#.view(b, c)
var = torch.var(x, dim=(2, 3)).view(b, c, 1, 1)
y *= (var + 1e-3).rsqrt()
#y = torch.cat((y, var), dim=1)
return self.attention(y).view(b, self.k)
class AttentiveGroupNorm(nn.GroupNorm):
def __init__(self, num_groups, num_channels, k, eps=1e-5):
super(AttentiveGroupNorm, self).__init__(num_groups, num_channels, eps=eps, affine=False)
self.k = k
self.weight_ = nn.Parameter(torch.Tensor(k, num_channels))
self.bias_ = nn.Parameter(torch.Tensor(k, num_channels))
self.attention_weights = AttentionWeights(num_channels, k)
self._init_params()
def _init_params(self):
nn.init.normal_(self.weight_, 1, 0.1)
nn.init.normal_(self.bias_, 0, 0.1)
def forward(self, input):
output = super(AttentiveGroupNorm, self).forward(input)
size = output.size()
y = self.attention_weights(input)
weight = y @ self.weight_
bias = y @ self.bias_
weight = weight.unsqueeze(-1).unsqueeze(-1).expand(size)
bias = bias.unsqueeze(-1).unsqueeze(-1).expand(size)
return weight * output + bias
TIDE: A General Toolbox for Identifying Object Detection Errors
这篇paper给了一个Python工具箱, 更为详细地去分析object detection的error,
Arbitrary-Oriented Object Detection with Circular Smooth Label
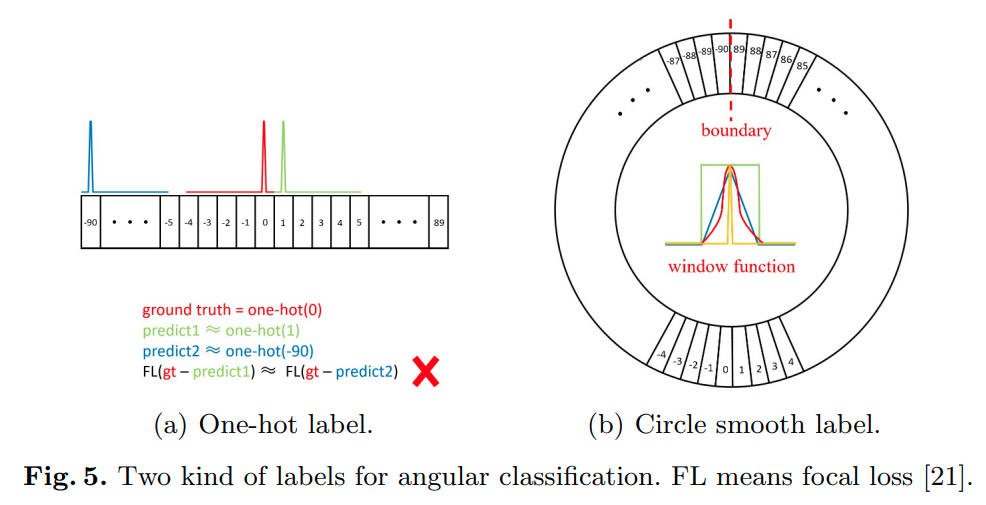
这篇paper review了回归旋转 bounding boxes的方法,同时指出了目前几个回归参数化方法的弊端,提出的方案主要是解决了角度的不连续性问题.
三种已有的参数化回归旋转bounding boxe的方法:
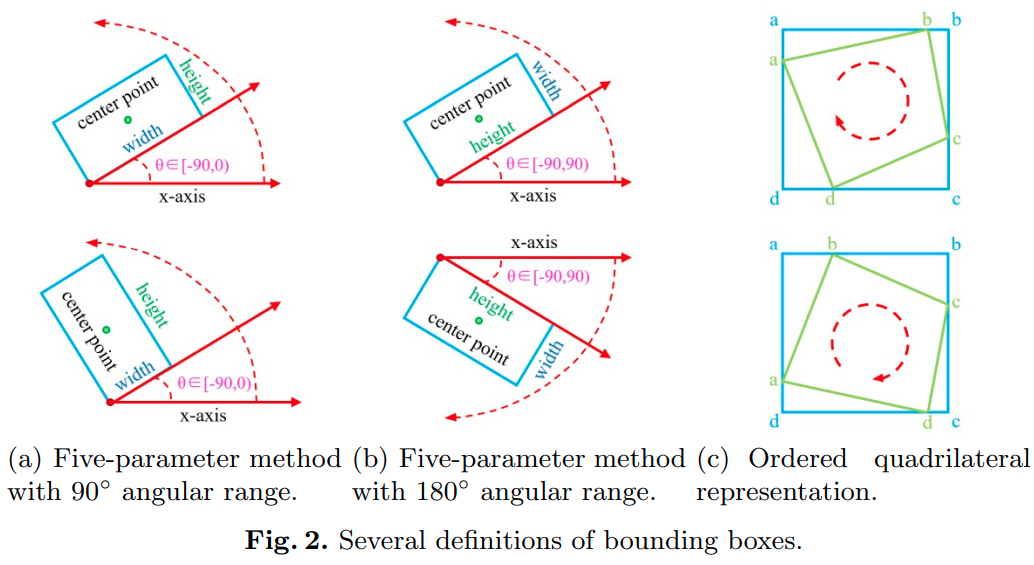
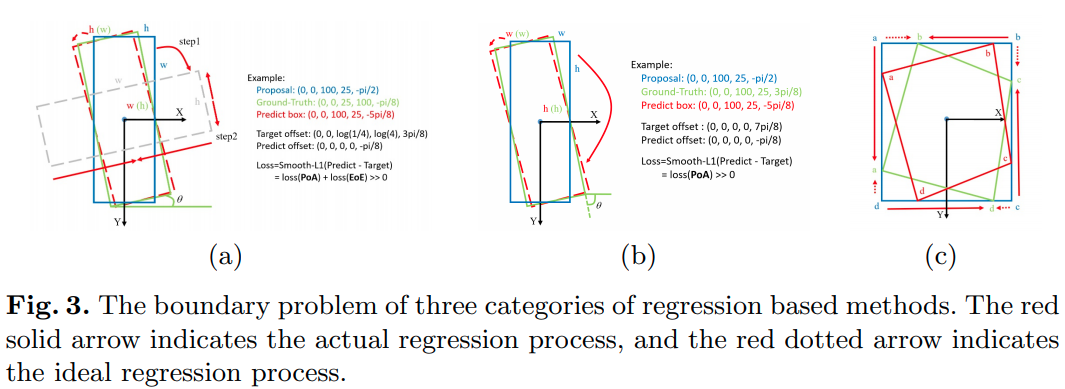
在某个特殊情况下,以上三种参数方法病态的回归过程:
作者提出在角度上采用窗函数平滑后的、基于分类的训练方案
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
这篇paper是eccv2020的best paper.对于光流的计算有比较大的创新。主要实现的是在高分辨率下对大尺度光流搜索的优化方案。
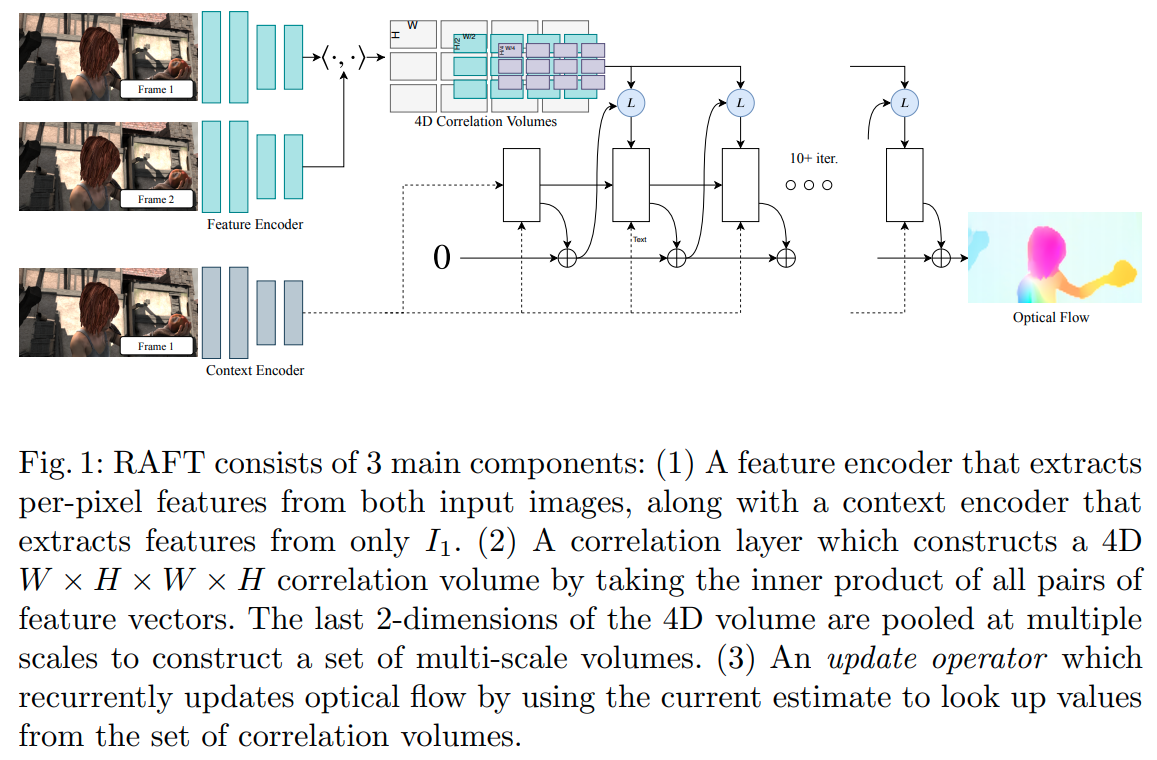

核心的创新在于在scale 8 预计算两帧之间每两个像素之间的匹配score(dot product),在迭代优化的过程中"LookUp" Operator负责将sample光流对应位置的cost. 避免了多次重复计算cost volume. 使得在scale 8上搜索长距离的光流成为可能,对快速移动的小物体的检测能力变强。