Composable Action-Conditioned Predictors: Flexible Off-Policy Learning for Robot Navigation
这篇论文提出了一个灵活的、少监督的增强学习导航框架。模型的学习过程使用较为有限的监督,同一个模型可在deploy时通过修改reward函数是的机器人达到我们想要的导航效果
CAPs模型介绍
CAPs结构的目的是通过输入的图片、状态序列,输出当前状态下几个重要的encoded event的相关参数。本论文使用的是collision, heading, or road lanes and doorways(门在图片中的比例)。过程是off-policy的,模型取决于一个长度为N的未来的action list,数据采集过程采用的policy与最终deploy没有必然联系。
在deploy的时候,用户基于encoded event定义新的reward function, 系统通过MPC优化实现控制。
深度学习结构
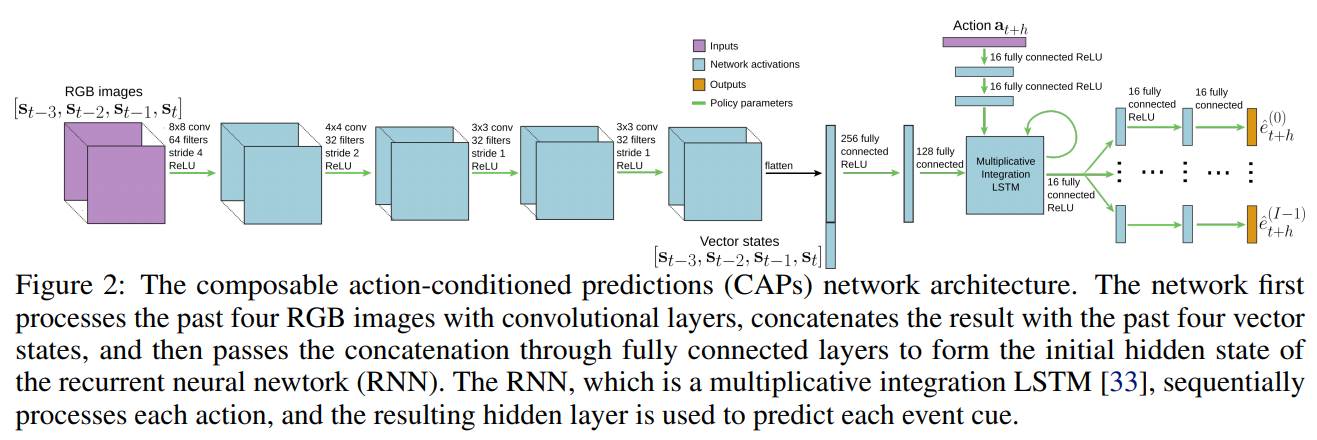
卷积提特征->concat状态向量->全连接->multiplicative integration LSTM的初始状态值->输入序列action->通过FC分支输出各个encoded event的参数
encoded events (event cues)
这里选择的collision以及heading以及速度等可以通过车身传感器测得自动标注,road lanes和doorways这里使用了一个pretrained FCN进行语义分割直接得到结果
三个实验项目
仿真森林走动
奖励函数为:
Carla仿真运行
奖励函数为
需要预测的内容包括:碰撞、速度、可见道路比率、可见道路比率变化率、朝向
实际车辆运行
需要预测的内容包括:碰撞、朝向、房间门占画面比率
它们为了训练Segmentation网络标注了训练过程中0.2%的图像数据。