VoteNet & ImVoteNet
另外ImVoteNet的pdf: pdf
这两篇paper是相关且连续的idea,这里连续阅读
VoteNet
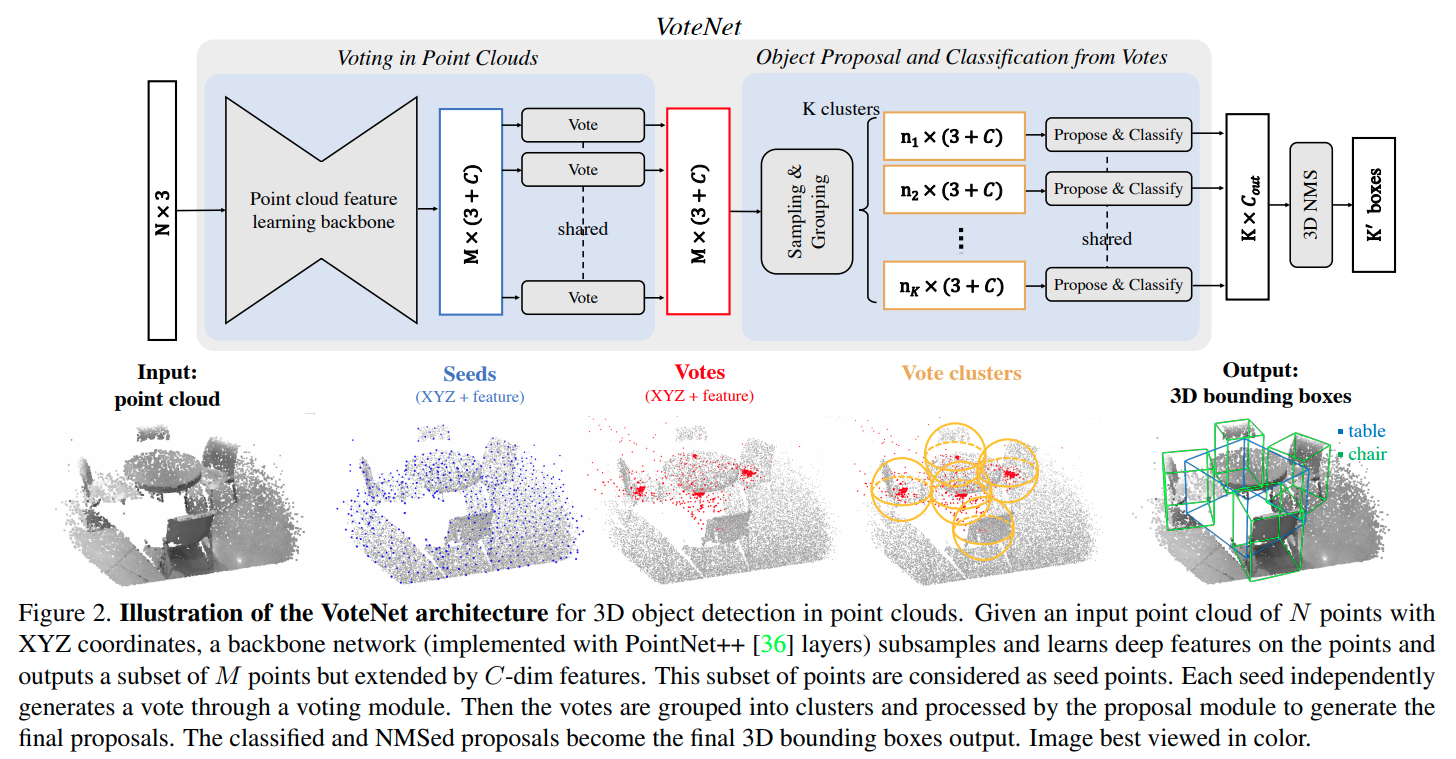
作者的理解是,由于点云与实际点的位置有一定的距离,因而inference 物体的中心有难度,这里借助hough-voting的思路.
算法pipeline:
使用PointNet++ 提取特征,使用最远点取样,下采样的到M个seed point.
每一个seedpoint 经过MLP,得到object 中心与seed point的以及特征残差.
根据最远点采样以及基础的threshold距离进行聚类。
每一个聚类里面的点用线性层进行融合, 其中为归一化的距离值,为每一个点的特征
ImVoteNet
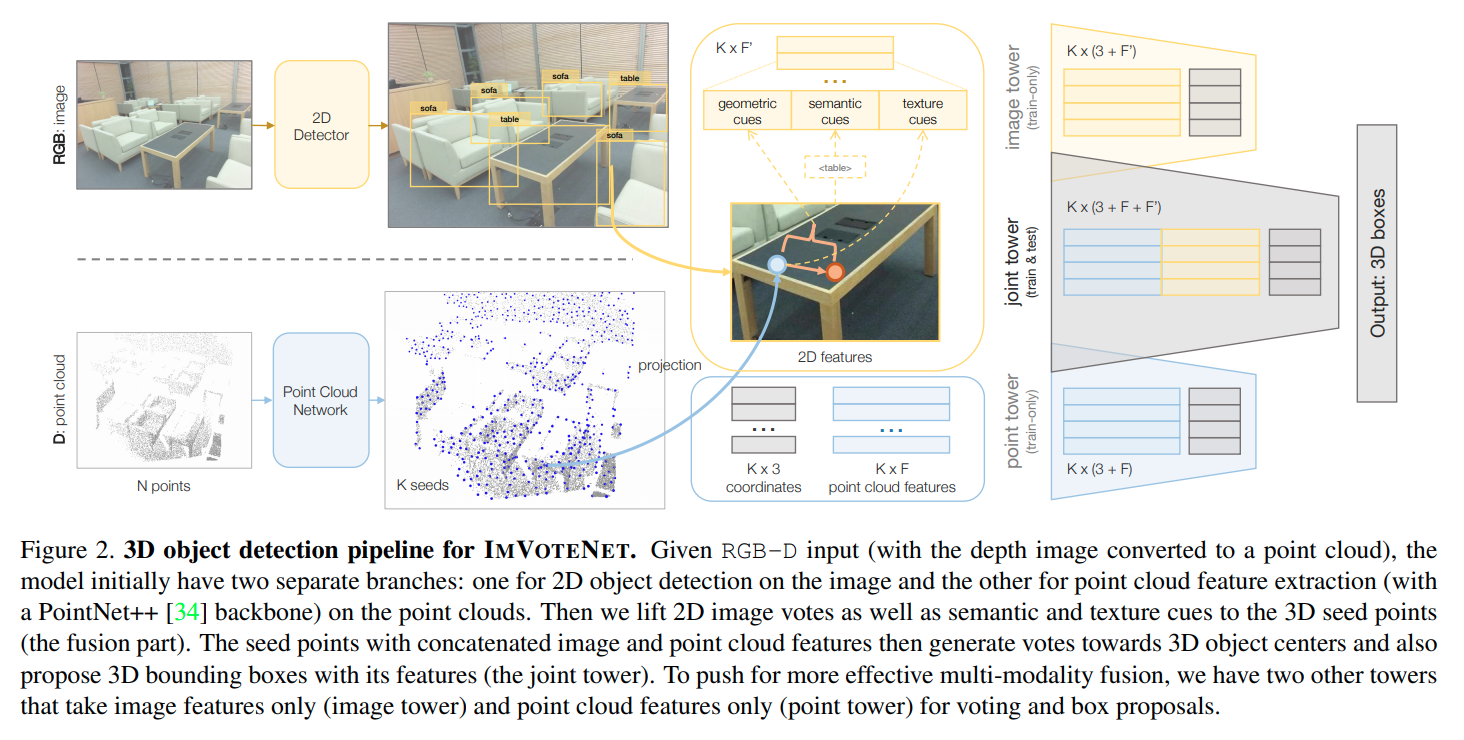
这篇论文在votenet的基础上解决两个问题,第一个是如何使用image detector辅助seed points进行voting,第二个是如何融合两者的feature 对最后的3D信息进行回归。
在第一个问题上,ImVoteNet的设定是2D detector的中心与物体的3D中心在同一个投影线上。如下图
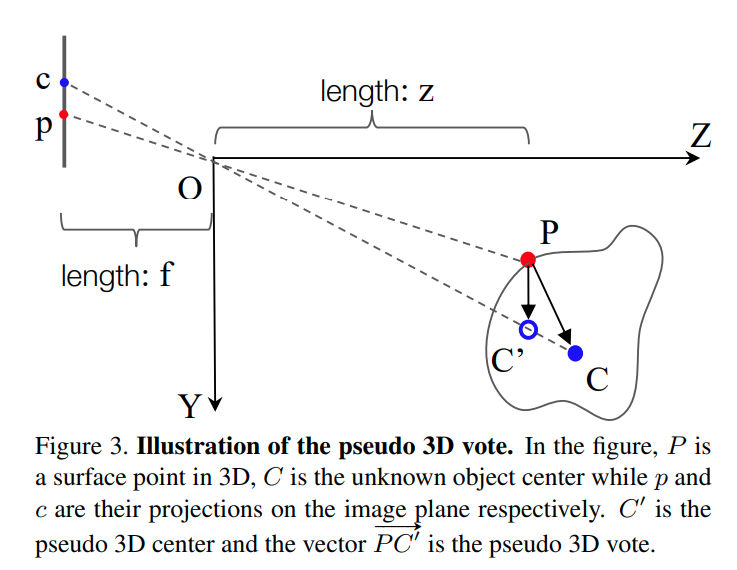
假设是物体上的点,也就是点云的一个点,点P产生vote时需要预测一个.现有的数据为点的三维坐标、在图片上的投影, 以及在图片中的投影.
3D voting时只需要再预测,降低了搜索空间。
关于第二个问题,作者提出使用三个与2D detector无关的feature
Geometric Cues for each seed point:
Semantic Cues for each seed point:
对应2D detector输出时的分类矢量(不使用RoI Align处理后的矢量,为了让这个网络与 detector 无关)
Texture Cues for each seed point:
将seed point投影到原来的RGB图上,将这个RGB vector 作为 texture cues赋予给这个点。
Fusion:
作者让点云、图片分别各自进行detection,training时直接融合。使用了gradient blending.pdf这个trick.