Summaries for several CVPR 2020 papers
目录:
- Summaries for several CVPR 2020 papers
- Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (ATSS)
- Depth Sensing Beyond LiDAR Range
- RetinaTrack
- MUXConv: Information Multiplexing in Convolutional Neural Networks
- Structure Aware Single-stage 3D Object Detection from Point Cloud
- Camouflaged Object Detection
- Lightweight Multi-View 3D Pose Estimation through Camera-Disentangled Representation
- Flow2Stereo: Effective Self-Supervised Learning of Optical Flow and Stereo Matching
- What You See is What You Get: Exploiting Visibility for 3D Object Detection
- Instance Shadow Detection
- A Model-driven Deep Neural Network for Single Image Rain Removal
- Single Image Optical Flow Estimation with an Event Camera
- - nets: Deep Polynomial Neural Networks
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (ATSS)
这篇paper做了一个相当细致对比实验来分析anchor based与anchor free模块的区别结果。另外自己提出了更好的sampling方法ATSS
传统的RetinaNet(32.5%)被anchor free的FCOS(37.8%)性能大幅超越,是什么引起了这些差距呢,是anchor free与anchor based本身吗?作者分析指出,对于一个每一个scale只有一个anchor box的 Retinanet模型与FCOS进行对比,训练细节的差别:1. GroupNorm 2. GIoU Loss 3. Center point should be in the Box 4. Centerness branch (also helpful in NMS)5. additional trainable scalar, 这里面比较重要的是(1),(2),(4).
RetinaNet与FCOS的本质区别有二,第一个是分类时给定正样本的方法。
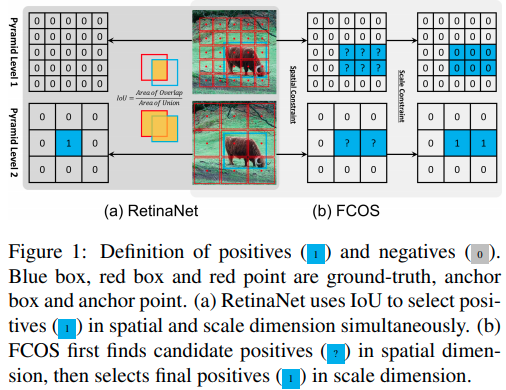
第二个是回归时框大小的回归方法.作者在下表实验说明了正负样本的分配策略才是影响点数的最重要因素。
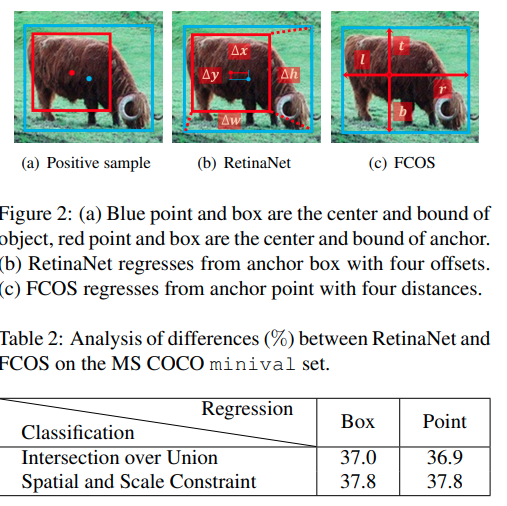
作者提出的ATSS算法.

Depth Sensing Beyond LiDAR Range
这篇paper是属于值得精读的文章之一。
Motivation
LiDAR一直以来存在着无法感知足够远的物体的问题,即使线数很大,有效的距离可能也就只能去到80米。而这个对于中速行驶的汽车来说仅仅是几秒内的里程,因而往往不够用。本文要实现超过一百米乃至本文给出的近300米范围内的深度估计,使用了特殊配置的多目摄像机(三目)。对于摄像机参数来说,就需要大分辨率,小感受野用于专注于远景,但是这个硬件配置的问题在于对微小的外参扰动非常敏感,因而需要鲁棒算法or在线补偿(本文的方案)。
硬件配置
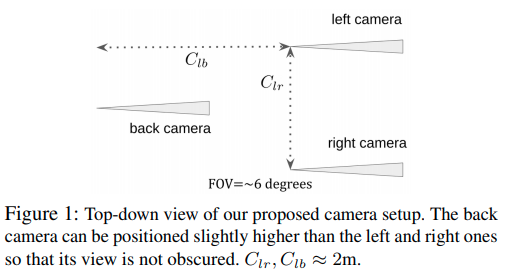
作者文中以及后面的计算同时指出,左右目的距离应该足够远,而且前后相机距离也应该尽可能远,这些都仅仅被车身大小所限制。
算法流程

 第一步进行的是retification,得到两个相机之间的一个相互转换,使得Stereo matching的epipolar line是水平的。作者简单地证明了,对于小FOV相机以及小扰动来说,关于x/y轴的微小旋转都近似等同于整个画面的平移。而画面的旋转本身就是一个Affine transform.因而实际上可以用homography transform matrix(2x3),就可以完成对原来图片的矫正。整个算法的思路就是使用RANSAC,决定H矩阵对应的参数。要求是让尽可能多的matched point都在同一个水平线上。可以想象的是,这样的retification方式无法决定相机关于y轴的旋转,因而warped后的图片计算得到的双目匹配disparity与正确的值之间有一个bias(可以理解为对旋转的估计的bias/ambiguity)
第一步进行的是retification,得到两个相机之间的一个相互转换,使得Stereo matching的epipolar line是水平的。作者简单地证明了,对于小FOV相机以及小扰动来说,关于x/y轴的微小旋转都近似等同于整个画面的平移。而画面的旋转本身就是一个Affine transform.因而实际上可以用homography transform matrix(2x3),就可以完成对原来图片的矫正。整个算法的思路就是使用RANSAC,决定H矩阵对应的参数。要求是让尽可能多的matched point都在同一个水平线上。可以想象的是,这样的retification方式无法决定相机关于y轴的旋转,因而warped后的图片计算得到的双目匹配disparity与正确的值之间有一个bias(可以理解为对旋转的估计的bias/ambiguity)
Disparity Estimation使用的是一个pretrained的stereo matching网络.

第三步是利用前后相机消除第一部分产生的ambiguity.对于左目上任意两个具有相同深度的pixel,这两个点在3D中,相对于前后摄像机的, 坐标的差是一致的(这里指的是相机参考系而不是图片参考系),这里引出以下推导。
对于一组符合, , 的点,由它们的数值可以得到的对disparity bias的估计为:
前面提到的这三个条件分别表示 (1) 这个batched是否事实上真实;靠前相机看到的两点距离理应更大 (2) 两个点的距离应该足够大,最好不要贴在一起 (3) 两个像素之间的距离几乎是相等的。
作者后面用: 1. 用仿真实验证明了很小的误差,在双目长距离匹配中就会很大的使性能退化。 2. 他们提出的retification方法与标准8点法对比在这个场景下数值更稳定;因为他们利用了这个场景下的先验知识。 3. 实验说明了ambiguity removal的过程,以及最后计算的有效性。
RetinaTrack
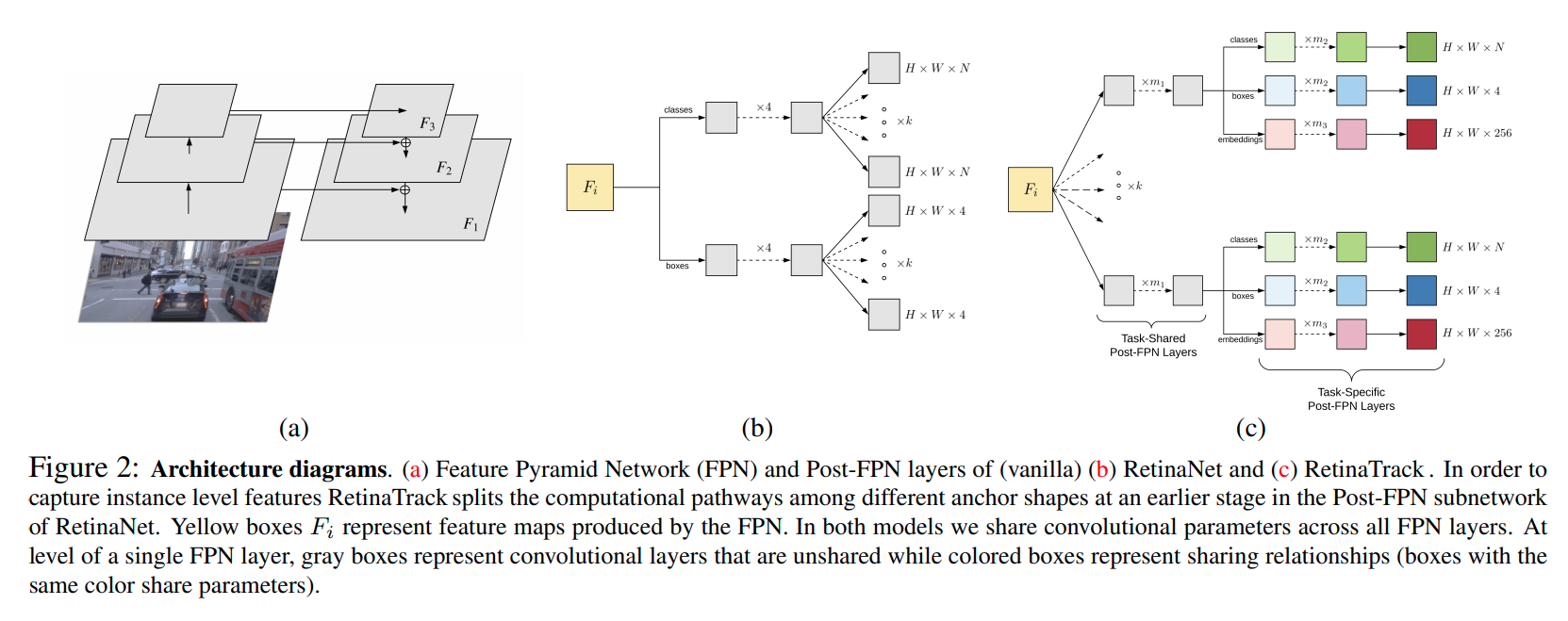
特点,不同anchor在更早期features就开始分开,每一个anchor输出一个256维度的features.
对单一图片用triplet loss
核心思路就是相同instance的不同anchor输出相似的embedding,不同instance的不同anchor输出不同的embedding。本文用基础的euclidean distance作为loss
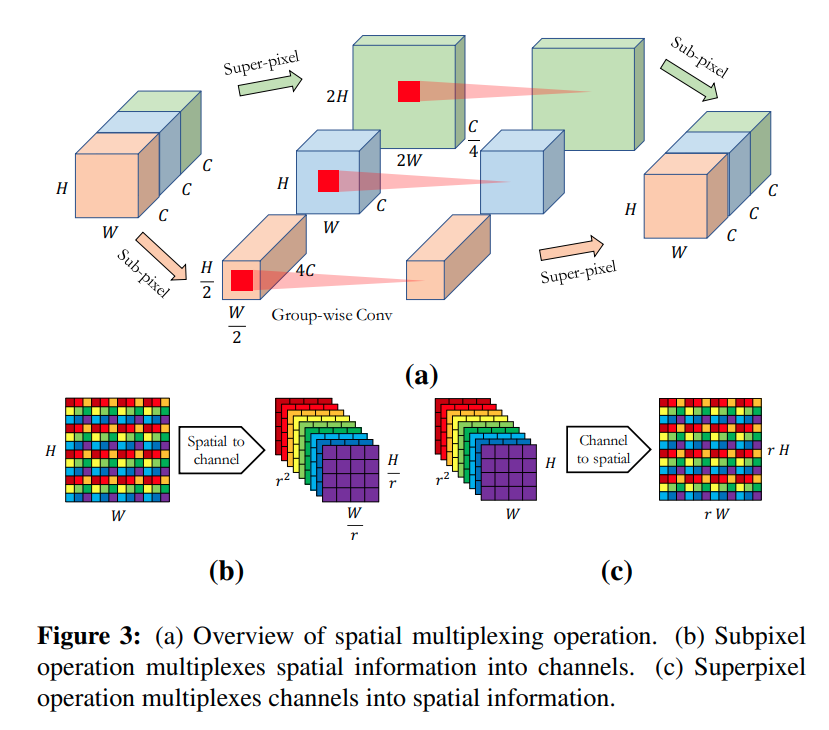
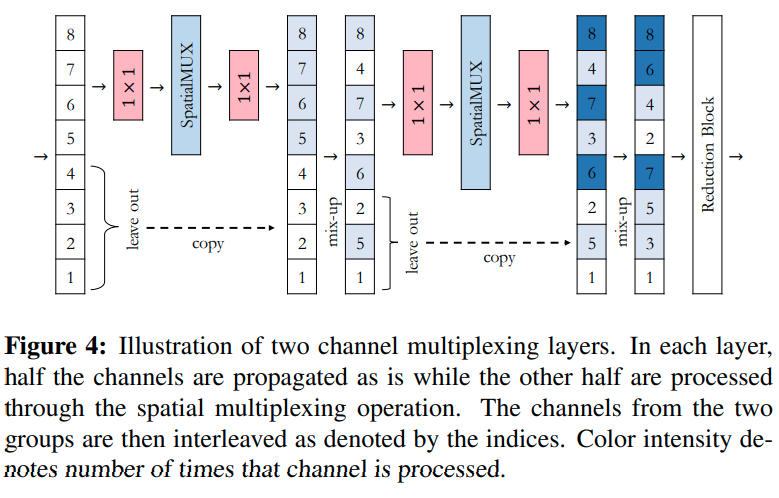
MUXConv: Information Multiplexing in Convolutional Neural Networks
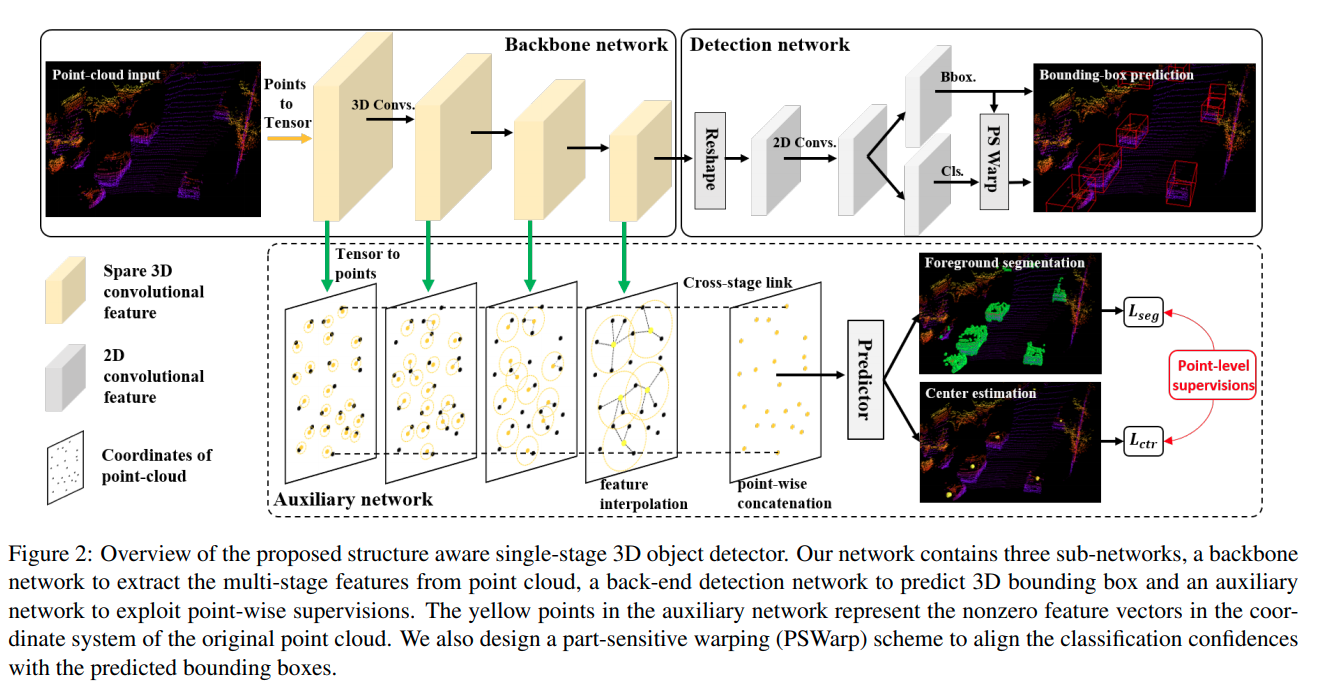
Structure Aware Single-stage 3D Object Detection from Point Cloud
基于MMdetection开发的点云3D 检测,性能很高,重点在于附加task的设计的,能让一个接近于VoxelNet的结构得到很大的提升
Camouflaged Object Detection
本问提出了一个新的问题以及新的数据集,有中文paper.

Lightweight Multi-View 3D Pose Estimation through Camera-Disentangled Representation
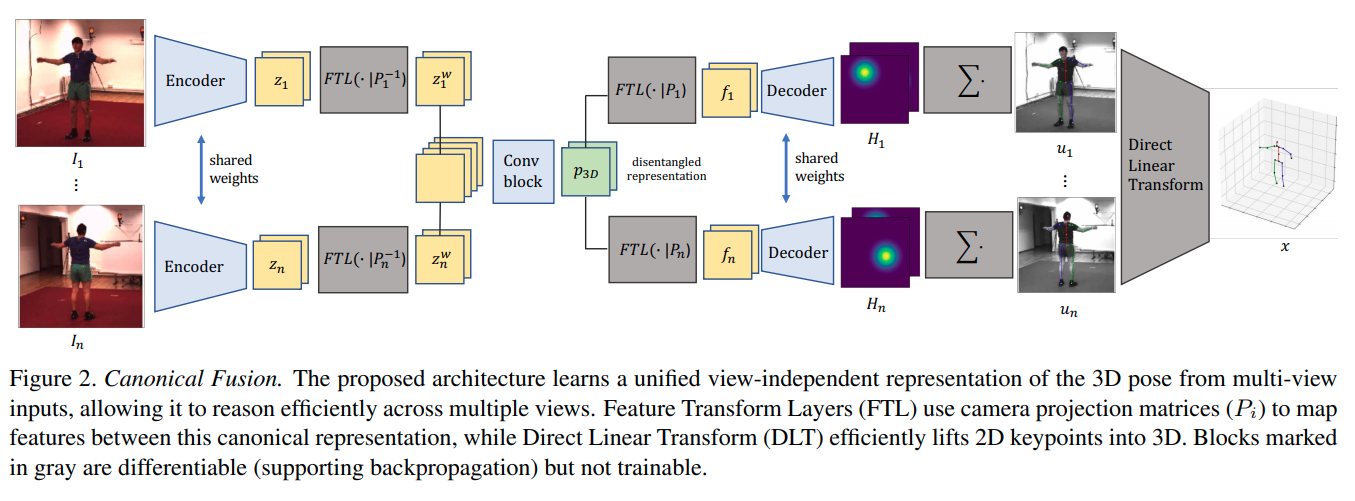
FTL层不是一个学习层,用一个全连接层,将2D预测用旋转变换转换到与camera方位无关的结果
3D 位置估计采用的是SFM的formulation
把同一个关节所有点放在一起,,原理上来说需要使用SVD找出最小特征值对应的特征向量。作者指出如果只需要求最小特征值,不需要使用SVD,使用以下迭代算法即可

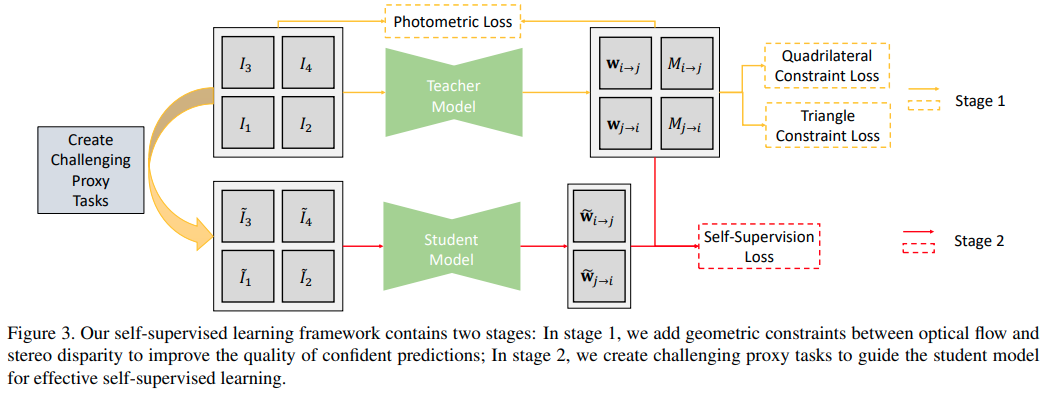
Flow2Stereo: Effective Self-Supervised Learning of Optical Flow and Stereo Matching
What You See is What You Get: Exploiting Visibility for 3D Object Detection
本文主要针对的就是Nuscene场景中被遮挡比较严重的物体。通过用点云建立的occupancy map,网络可以infer什么地方是可能被遮挡而可能有物体的。
本文有一个比较好的中文博客,提到了本文几个重要的有趣的细节,第一个是3D世界的Fast Voxel Traversal生成occupancy map;第二个是数据增强,采取的方法与occupancy map进行增强;第三个是online bayesian grid mapping.
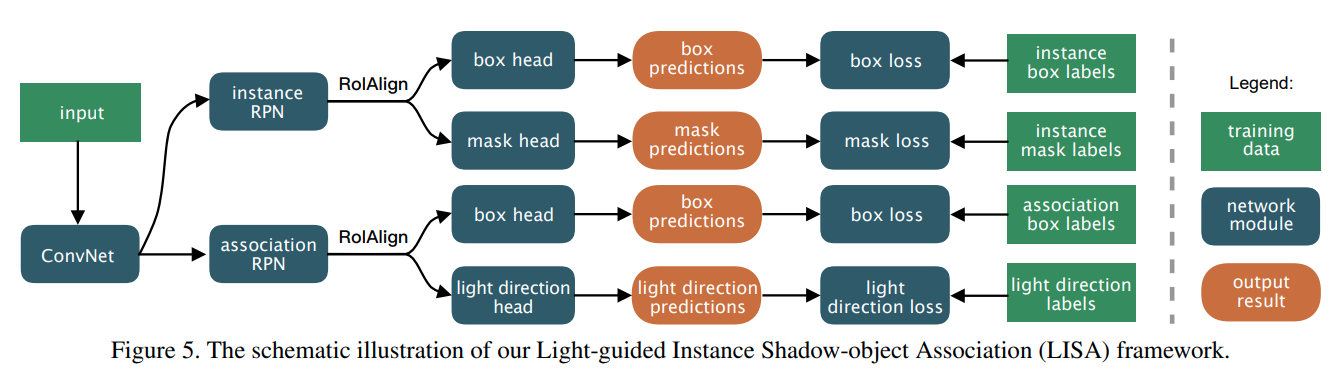
Instance Shadow Detection
本文提出了一个新的任务,新的dataset以及baseline方法。任务是物体与影子的instance segmentation以及一一对应。
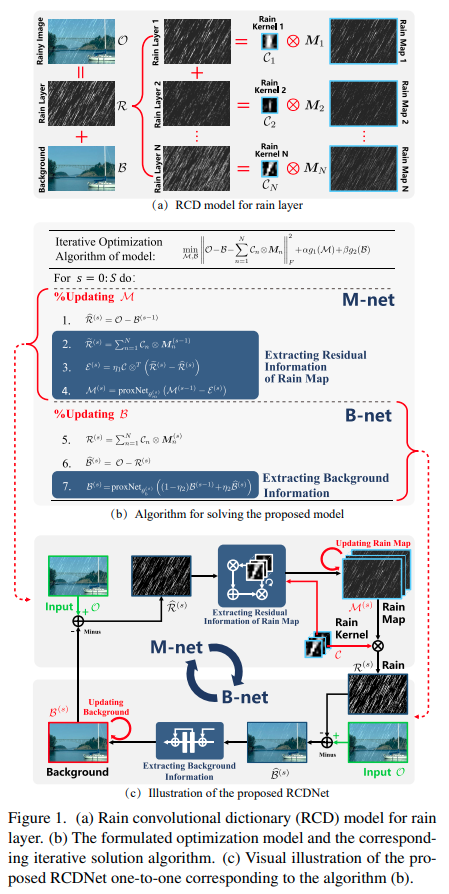
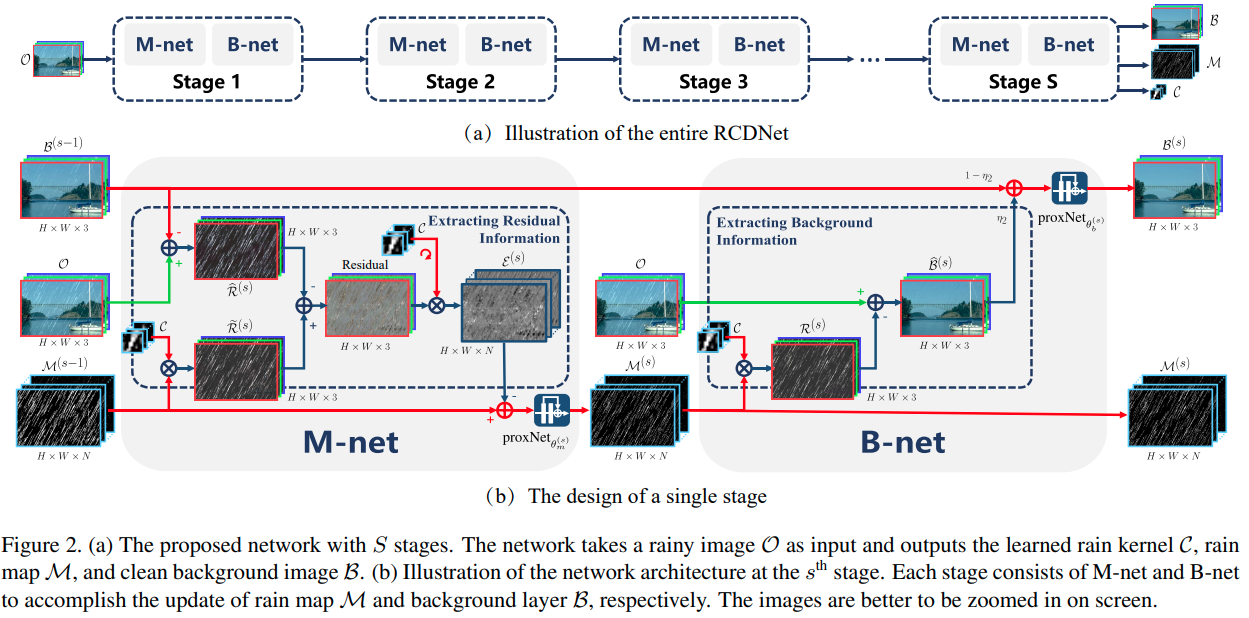
A Model-driven Deep Neural Network for Single Image Rain Removal
Single Image Optical Flow Estimation with an Event Camera
本文是基于DAVIS的event + gray scale设计的算法,一个重要的idea是event信息本身可以直接存储光流相关的信息,而灰度图的动态模糊也可以用于指引光流估计。因此本文提出同时估计光流场以及latent image .
能量函数设计为
首先是考虑了光照变化的光流-光照一致条件
模糊: 模糊后的图片可以由模糊核以及latent 图片卷积表达:
模糊条件:
后两项为连续性要求,文中的设计比较精细。 优化方法上本文迭代进行光流估计以及图片的deblur
- nets: Deep Polynomial Neural Networks
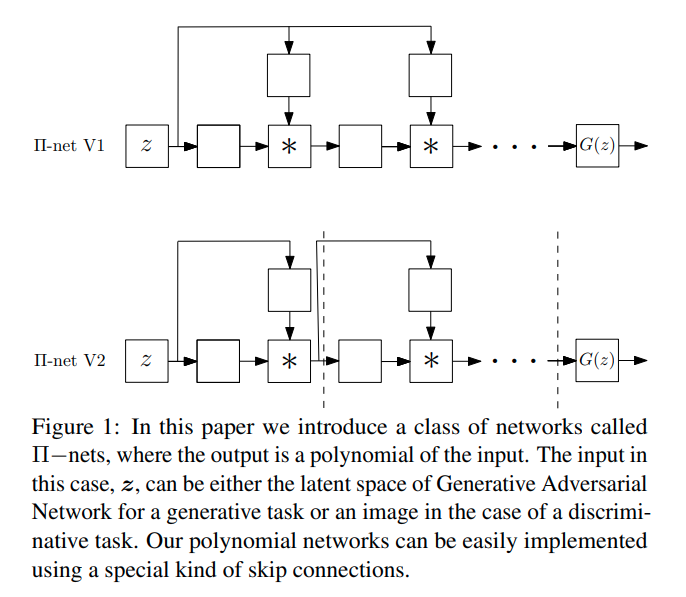
可学习参数的多项式计算模块(最终输出为输入的多项式表达)