Neural Tangent Kernel: Convergence and Generalization in Neural Networks
这篇paper是 2018 NIPS一篇比较有影响力的paper
Prior Experiments
这里先根据这个code demonstration 补充说明几个重要的直觉概念.
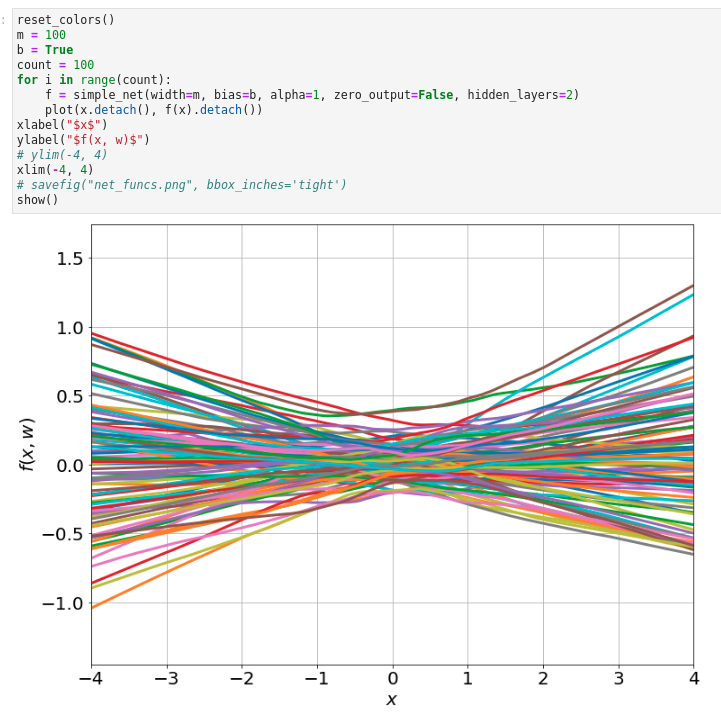
随机初始化100个单输入单输出100个隐藏单元的两层神经网络,这些网络的输出接近于一个在0附近的高斯过程的输出分布.
对于一个只有(0, 0)数据的高斯过程
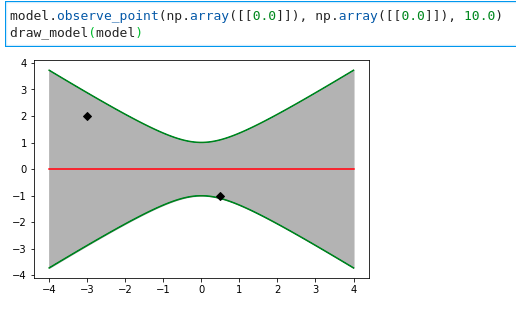
在一个小数据集上训练,训练过程
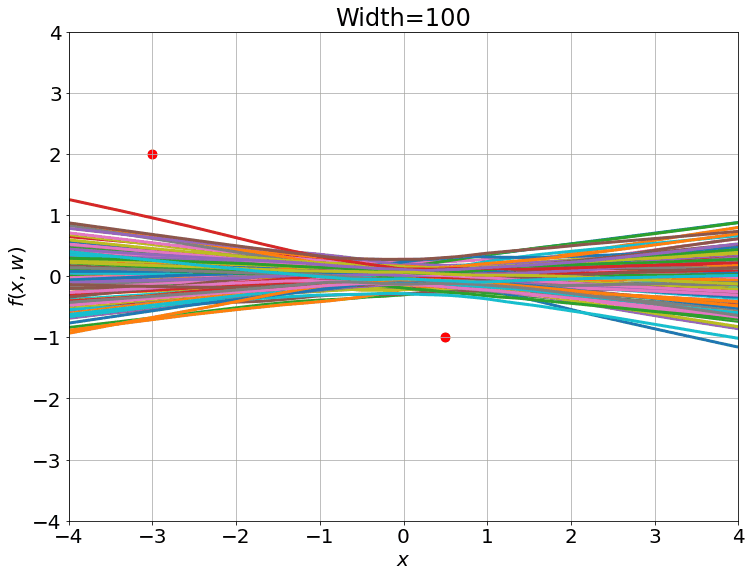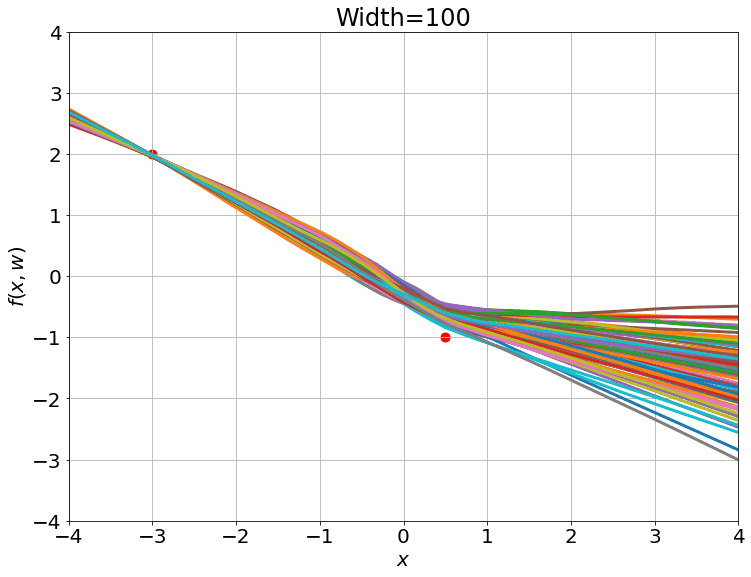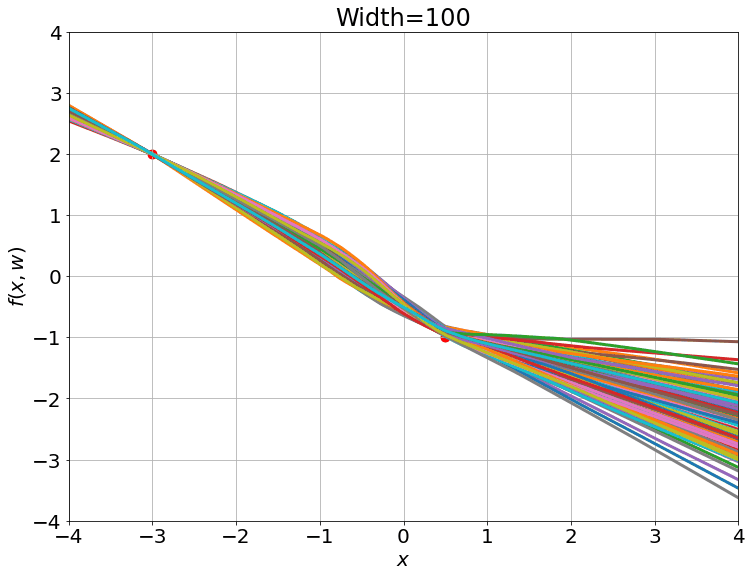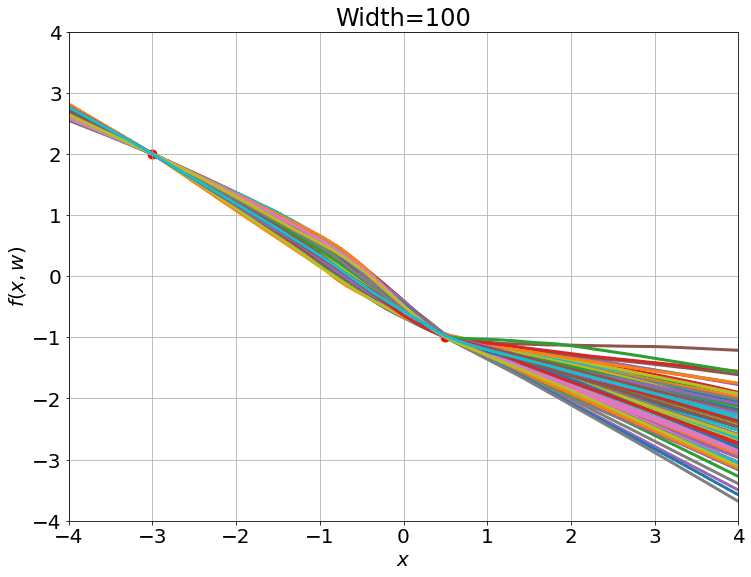
高斯过程的结果
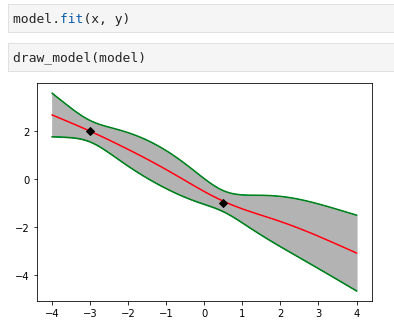
一个比较抽象的结论就是无限宽的神经网络等价于高斯过程。
第二个结论是训练过程权重的相对变化是很小的
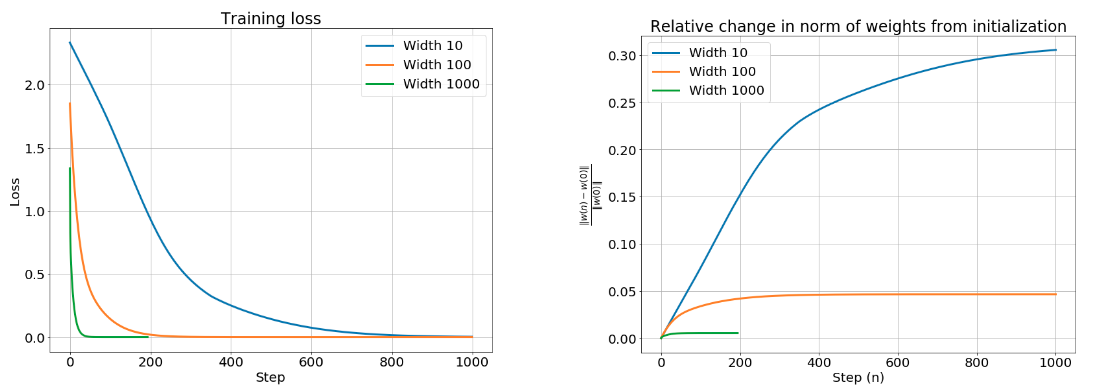
NTK
对网络进行泰勒展开
可以证明随着网络宽度增大,
网络的权重的变化为 , 其关于时间的微分为
则输出值的变化率,
神经网络的梯度雅克比矩阵,
NTK指的就是 .
可以证明过参数网络会以指数速度收敛于训练损失为零的位置。 解释网络为什么可以训练
同时可以发现这个NTK由于梯度下降的原因,会有一个implicit l2-norm (相当于有一个0-0的数据点). 解释网络为什么可以generalize