SUNRISE: A Simple Unified Framework for Ensemble Learning in Deep Reinforcement Learning
这篇论文是基于SAC的一个扩展算法,有比较好的一个知乎文章介绍.
Preview - SAC
Soft-Actor-Critic (SAC)是一个SOTA的 model-free 连续RL算法. 知乎文章介绍
关键的一些特征:
- Off-policy, 使用replay buffer.
- actor 网络输出mean, variance。 重整化采样后,在收集replay buffer的过程中输出的是随机的策略。
- 在最大化奖励的同时最大化策略的熵, Q function的训练损失为: Actor 的训练目标为:
- double-Q trick. 会训练两个Q网络,actor的训练目标中取两个Q网络中的最小值。
Sunrise
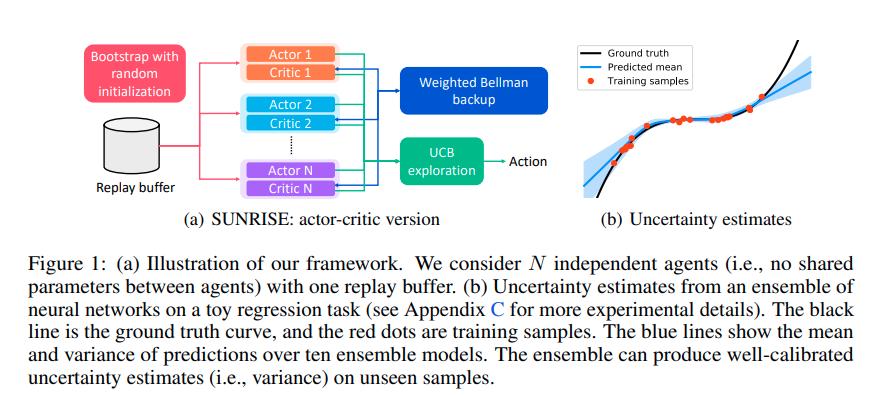
在SAC的基础上融合了三个关键点.
- 随机初始化,同时训练个SAC agent(个actor 和 critics). 且在采集replay buffer的时候会随机生成一个维的binary mask, 在训练这个样本的时候,根据binary mask选择不同的agent来训练,这个技巧可以保证不同agent的diversity (注意在决定采集的action的时候会综合考虑全部的agent的输出, binary mask只影响这个样本用于训练的时候的效果).
- 带有权重的Bellman更新。 在训练Q函数的时候,对于每一个"target Q"样本输入, 计算一个权重. 那么用于训练critics的损失函数都乘上这个权重.
- Upper Confidence Bound(UCB, 置信上限) 探索。在探索并收集replay buffer的时候,寻找. 这个最大化的严谨解是很难求的,本文的近似做法是让个actor生成个action 候选,然后分别在个critics上计算这个个 action的的均值与方差。
