Uncertainty Propagation in Neural Network
本文主要讨论不确定性在神经网络中的传播的一个方法。
在Bayesian Neural Network中,有两个流派,第一个是把每一个weight建模为一个高斯分布,另一个是把输入与激活建模为概率分布,而weight只是常数。
这里分享一篇在Robotics中应用第二种BNN的paper,在这之前分享本文的主要数学前置,
Lightweight Probabilistic Deep Networks
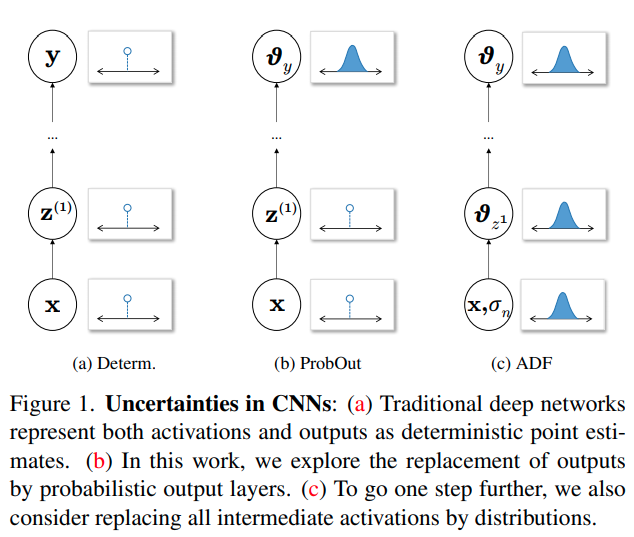
本文直接介绍ADF,将中间所有的激活层都理解为概率分布.
对于一个标准的神经网络前向传递,可以用概率解读,写为:
我们开始假设,网络的输入层有噪音,可以用element-wise的高斯分布建模(注意这里将输入噪音设定为各个元素独立的无味的误差, aleatoric uncertaint)。
高斯分布在网络传播中,尤其是非线性层传播后显然不再是高斯分布。作者指出,为了更好的建模传播后的均值与方差,要求用一个与实际分布的KL divergence尽可能小的分布,这篇paper指出这等价于让概率分布的矩相等,在高斯假设下,就是均值与方差相等(高斯只有两个参数,只能控制前两阶的矩)。
对于卷积层以及普通全连接层,本质上来说它们都是线性层,方差与均值的计算是解耦的。
指element-wise相乘,在implementation时,可以发现运算规则与原来的Forward是一致的,用不同的weight和bias就可以了。
对于ReLU,这篇paper证明了:
其中 且是标准正太的累计函数,是标准正态函数密度函数
对于MaxPooling,这篇paper指出,对于两个高斯函数:
迭代将所有需要处理的元素逐个Max运算。顺序是有相关的,但是本文建议为了提速可以尽可能并行,先水平再竖直方向,直接分开计算。
A General Framework for Uncertainty Estimation in Deep Learning
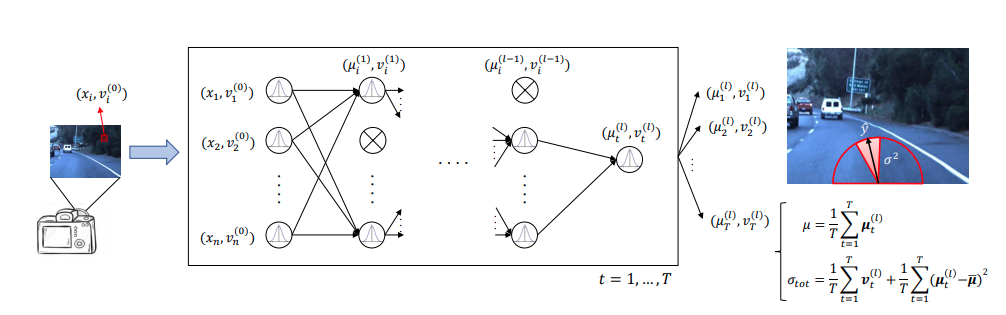
本文在end-to-end learning上综合两种bayesian uncertainty,第一个是由输入数据不确定性向后传播的结果。第二个是次采样Dropout,得到个不同的结果如图融合。