FreeAnchor: Learning to Match Anchors for Visual Object Detection
这篇论文来自于NIPS2019,介绍了新的方式来实现2D object detection中的matching.
总体思路来说,使用最大似然估计的框架在Object Detection的过程中,采用一个单一的loss,同时完成proposal与object的匹配以及回归训练,将中间matching步骤自动化了
核心算法

- 网络正常前传给出一系列的anchor box,每一个anchor box有分类以及localization信息
- 对每一个障碍物,选择与它IOU最大的n个anchor,带有一个threshold,如果一个anchor与多个物体匹配, 则使这个anchor只与IOU最大那个物体匹配(是否有这个限制需要看具体代码实现)
- 对当前的匹配分配计算一个Loss
- 反传训练
基于最大似然估计的匹配Loss
先给出最终的公式
其中 代表每一个物体对应的anchor bag的Likelihood ,第二项则代表没有被选入anchor bag的anchor作为background的Focal Loss,Focal Loss源自与这篇文章,直觉就是对于把握已经很大的正确的点降低权重, 对难度较大的部分增加它们在cost中的权重。
第一项、Mean-max以及概率定义
Mean-max函数表达式为:
其对应的函数图像为
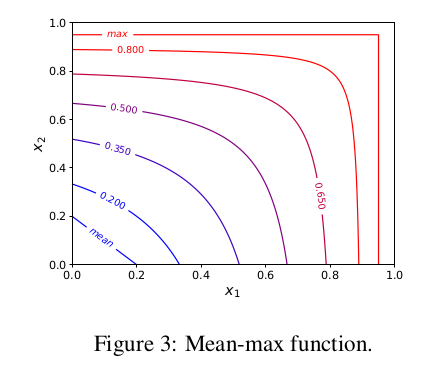
直觉来说,就是当likelihood函数值较小,网络刚初始化的时候,函数结果近似于各个数的平均值, 当有部分likelihood函数较大,网络训练成熟之后,函数结果近似于各个数的max.
根据作者的设计
, Loc同理,皆为对应基础cost函数值的负指数
Background项定义
指proposal框不与所有物体重合的概率 其中