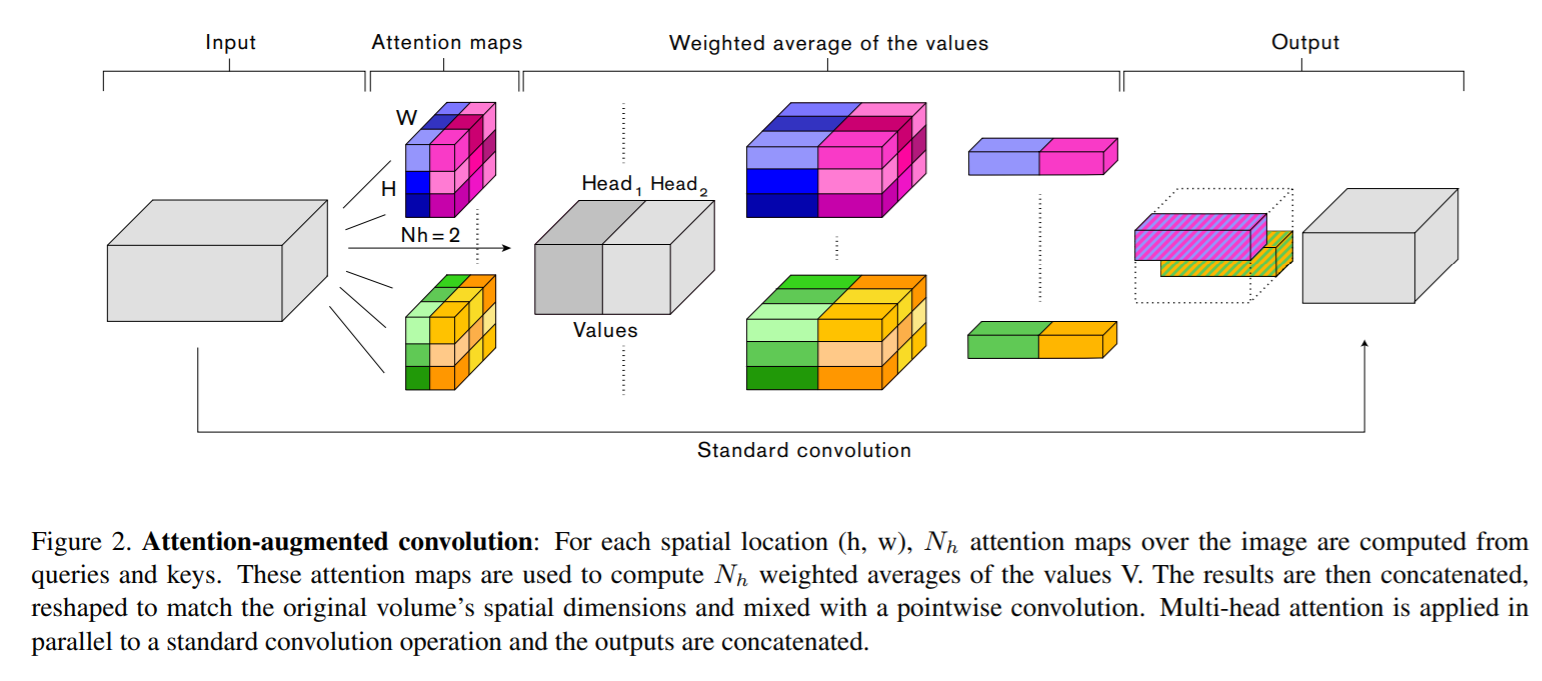
Attention Augmented Convolutional Networks
这篇文章基于transformer,将attention直接附加在卷积层中,理论上来说可以用于替代卷积层.
图片上的self-attention
设输入张量形状为,这里忽略Batch.首先摊平为一维变为矢量,然后直接使用transformer中的自注意力层
其中分别是输出维度为的全连接层的权重矩阵。
输出再Concat为MHA
最后会被reshape成为的形状.
二维positional embedding
同transformer,我们需要一个传递相对位置信息的方式,我们要求这个embedding能够使网络对位置敏感,但是不能让网络对平移敏感,这里来源来自于music transformer.
像素对像素的attention logits为 其中是像素对应的query vector,是像素的key vector,
上文的self-Attention计算可以转化为 也就是softmax分子加了两项,其中。
论文说这个的一种做法是直接存成一个矩阵,但是这样不太好,所以采取了Music Transform的算法,更省内存,具体看代码(原文就是这样),这些参数可学习。
Attention Augmented conv