Convex Optimization
本文主要收集在凸优化课程中记下的基础概念与结论。
- Convex Optimization
- 凸函数与凸集
- 凸优化问题
- 对偶与KKT条件
- CVX库
- 最优化算法
- Majorization-Minimization Algorithm (MM Algo.)
- Geometric programming
- 滤波器设计
- Markowitz Modern Portfolio Theory
- Constrained Problem Optimized for Sparsity
- Sparse Index Tracking
凸函数与凸集
基本定义与重要判定
- 凸函数要求函数上,任意两点间的函数值的线性插值要不小于线性插值的函数值.
- 凸集要求集合内两点连线上的任意点都在该集合内
凸函数的一个充分条件是二次导不小于零,严格来说是对各变量的Hessian Matrix为半正定.
常见而重要的凹凸函数函数
- 线性函数同时为凹、凸函数
- 所有的 norm (满足三角形不等式)都是凸函数
- 二次函数 , if 是凸函数.
- 几何平均 是凹函数
- log-sum-exp 为凸函数
- quadratic over linear 为凸函数
- log-det 为凹函数 (证明比较取巧,取定义域内任意两点,证明直线上插值比例为变量的函数都为凹函数,则整个函数为凹函数)
- 矩阵的最大特征值 为凸函数 (由最大值性质)
保留凸特性的常见操作
- 凸函数的非负权重求和
- 与线性函数的嵌套
- 多个凸函数的point-wise maximum.
- 凸函数中部分变量的maximum
凸优化问题
要求:
- 为凸函数
- 为凸函数
- 为线性函数,也就是只允许
主要性质:
凸优化的局部最优等于全局最优,且唯一.
将 , 转换为凸优化问题
问题可以如此转换: 变成
:
对偶与KKT条件
对于一般最优化问题:
Lagrangian为:
对偶函数
无论原来的问题是否是凸优化问题,对偶函数一定为凹函数 (线性函数的inf下界组合),因而最大化经常是一个凸优化问题.
同时, 对偶函数可以表征原最优化问题的优化下界。
对偶问题就是通过计算的最大值(同时有约束 ),来分析原问题的最优下界。
强弱对偶性
对偶问题得到的最优解 . 对于强对偶问题,则有
最简单常用的的判断原问题为强对偶的条件:
- 原问题是凸优化问题
- 且将不等式约束改为更强的约束,仍存在可行域.
线性不等式约束不需要满足第二条条件。这两点在大多数现实凸优化问题中都成立,大多数的凸优化问题都是强对偶的。
KKT 条件
- 主可行性, ,
- 对偶可行性,
- Complementary slackness
- 拉格朗日函数对每一个变量的导数(或者说梯度矢量)为零:
主要性质:
- KKT条件是任何一个可导的最优化问题的必要条件,也即是说最优解一定满足KKT条件
- KKT条件对凸优化问题来说是最优解的充要条件,也即是说可以用KKT条件求出来的解也一定是全局最优解。
计算与解题:
利用KKT条件直接求解的时候经常会遇到分类讨论,主要问题在于是否为零,物理意义上来说就是解是在边界上还是可行域内。可以用这一个反推回各种情况下对系统参数的要求。
同时记录常用的矩阵求导结果
CVX库
python中可以使用cvxpy库对凸优化问题进行建模与求解。理论上来说cvxpy库可以接受比较复杂的问题描述,然后库会尝试将问题转换为标准凸优化问题并调用求解器求解. 老师的建议是用来快速验证一个问题是不是凸优化问题.
最优化算法
以最小化为例子
牛顿法
承接梯度下降法, 牛顿法通过二阶导辅助确定步长:
内点法
对于不等式约束,可以理解为阶跃到无穷的一个损失项,使用Log惩罚函数软化此约束:
- 当t很小的时候,最优化几乎只优化不等式约束。
- 当t很大的时候,最优化几乎只优化原目标函数,但是在边界附近接近于阶跃。
直接来说,当t很大的时候,函数不好优化,因而需要迭代优化.

作业一道题就是要求使用barrier method 处理Lasso regression.
Block Coordinate Descent (BCD)
固定一部分解,每一步只对其中一部分解进行最优化迭代。
Majorization-Minimization Algorithm (MM Algo.)
对于通用优化问题
迭代的优化一个surrogate function.
要求:
- 在处相等且相切
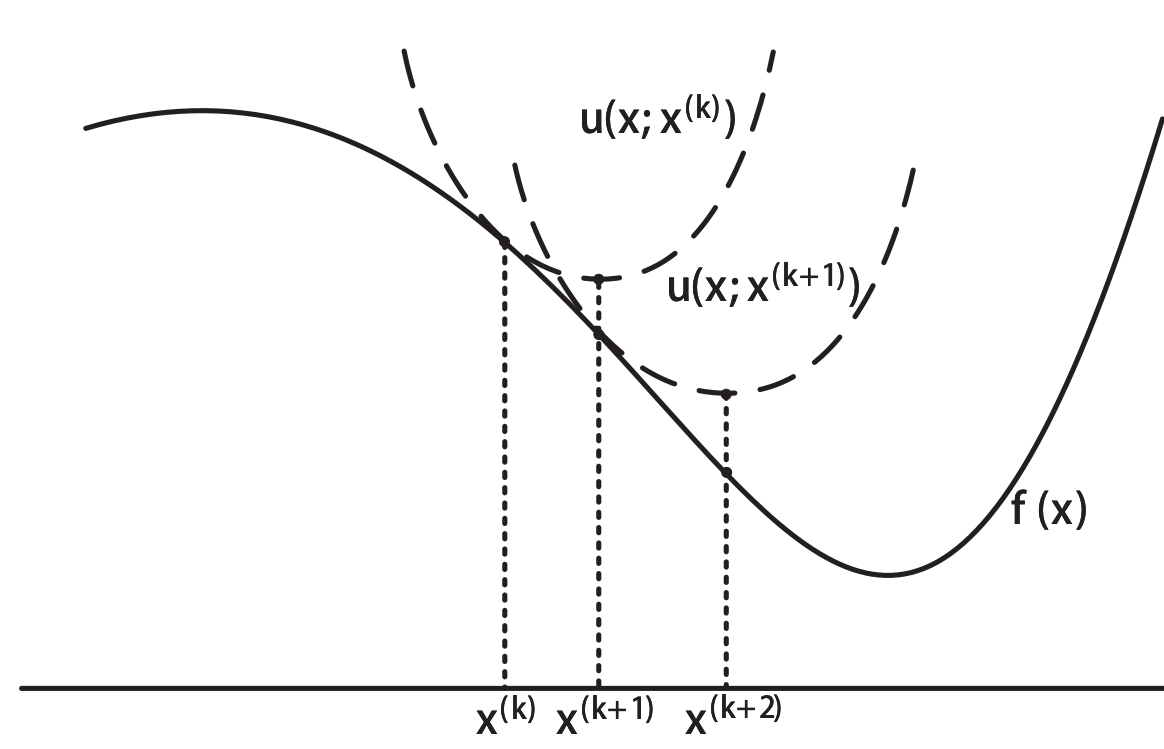
作业有一道编码题要求使用MM求解
Expectation-Maximization EM 算法属于 MM.
寻找 surrogate function的技巧
Convexity:
凸函数: 例子: 其中
Taylor, upper bound with quadratic terms
这个可以用也可以用
二次矩阵式 (Lecturer 的成果)
对于对称矩阵, 有对称矩阵 ,使得
其中往往可取
Geometric programming
概念定义
- monomial: , 要求
- Posynomial:
GP 定义: 其中 为posynomials, 为 monomials.
问题来源:
- 最大化容器体积
- 约束所有墙(地面与侧边墙体)的表面积
- 约束长宽比,高宽比等
求解方案:
将所有变量 用 替换, 对目标函数,约束取
目标函数都变为 log-exp-sum 的形式,因而为凸函数.
滤波器设计
切比雪夫滤波器设计
问题定义: 设计滤波器的线性参数 使得结果的滤波器与目标滤波器在目标频率范围内最大偏差最小化
由于滤波器的特性是一个虚数函数,因而 "| |"符号并不是绝对值而是模长,对离散采样,使用epigraph转换问题,最终可以得到这个SOCP
magnitude 优化问题
约束是 。 显然左侧的大于号是非凸的。这里使用自相关系数的概念。自相关系数 自相关系数的傅里叶变换结果 (功率谱函数),可以观察到, 与是线性关系. 将原来的约束转换为 , 这个不等式对是线性,凸的。因而幅值优化问题一般解决方法是将问题转换为关于的函数,然后用spectral factorization将重新转换为
Log-切比雪夫 幅值设计
优化问题专注于幅值的分贝值,优化是要求最小化与目标谱的偏差
其中指的是目标的函数的幅值函数.
解决方案:
- 引入新变量 , epigraph重写max函数
- 将问题转换为功率谱函数问题 .注意 是关于线性的.
- 利用对数与指数的单调性,不等式两边同时取,换元, 同时将优化问题从优化直接改为优化
反比例函数与线性函数都满足凸优化条件,问题划归为凸优化问题.
Markowitz Modern Portfolio Theory
这个金融学问题是一个讨论投资决策的简单模型。其将每一项投资的报酬理解为一个高斯分布;不同的投资组成的联合分布是一个(可能)有相关性的多元高斯分布;投资者的决策,也就是投资组合是资产的加权组合;投资组合的报酬也将会是一个高斯分布. 投资者的决策将会是最大化投资组合的期望收入,同时希望减少投资报酬的不确定性.
基础问题一: mean-variance portfolio (MVP)
使用KKT可以直接得到结果。 拓展思考,进一步考虑到以及都是从数据样本的均值与方差中估计出来的,因而这个优化问题可以理解为对样本数据的 -regularized的回归问题.
通过添加一些新的简单约束,可以在不影响凸优化性质的基础上使结果更鲁棒.
基础问题二: Global minimum variance portfolio
同样可以通过KKT条件直接得到结果
困难问题: Maximum Sharpe ratio portfolio (MSRP)
这个问题并不是凸优化问题,但是可以被归纳为 concave-convex single-ratio fractional programming. 也就是最大化一个 分子为非负凹函数;分母为非负凸函数的函数. 其一般形式为 这里介绍了三种解法
二分求解
写成epigraph形式,
如果将设为常量,这个问题会变成一个凸优化问题,而且是可行性问题.
使用二分法不断收敛的取值范围,找到最大的存在解的,对应的优化结果为目的结果。
Dinkelbach Transform
将问题转换为
其中新变量会被迭代地更新,
Dinkelbach证明了 是单调递增的,且结果最终会收敛到 concave-convex FP的最优解.
Charnes-Cooper Transform / Schaible transform
对于线性的, 分母都大于零的情况. 可以采用Charnes-Cooper转换。
线性FP: 换元 , 问题可以变为 问题变成了一个Linear programming.
Shaible Transform是以上运算的推广,通用地来说, 可以设, , 约束问题变为 $$ 要满足原来的约束} \end{aligned} $$ 这三种方法都可以用于求解原来的MSRP问题.
Constrained Problem Optimized for Sparsity
Iterative Reweighted l1-Norm Heuristic
- set repeat:
- subject to constrained.
- Convergence
直觉:
- 第一次迭代为直接优化-norm
- 之后每次迭代
- 如果比较小,惩罚权重比较大,驱使它更小
- 如果比较大,惩罚权重比较小,且梯度也不大,允许它变得更大.
理论分析
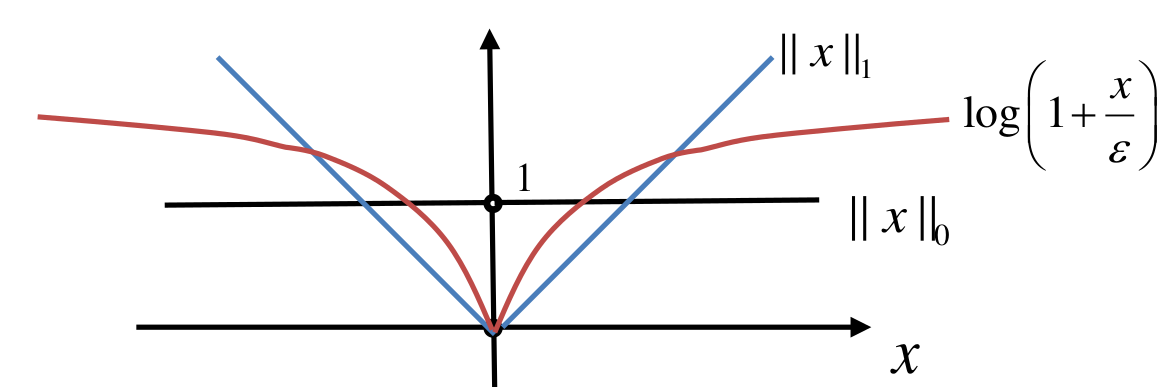
使用而不是来对进行拟合.
优化问题变为
对于这个问题, 思路是使用 MM算法,代理函数选择切线拟合:
问题最终变为求解一个带约束的线性目标函数
其中
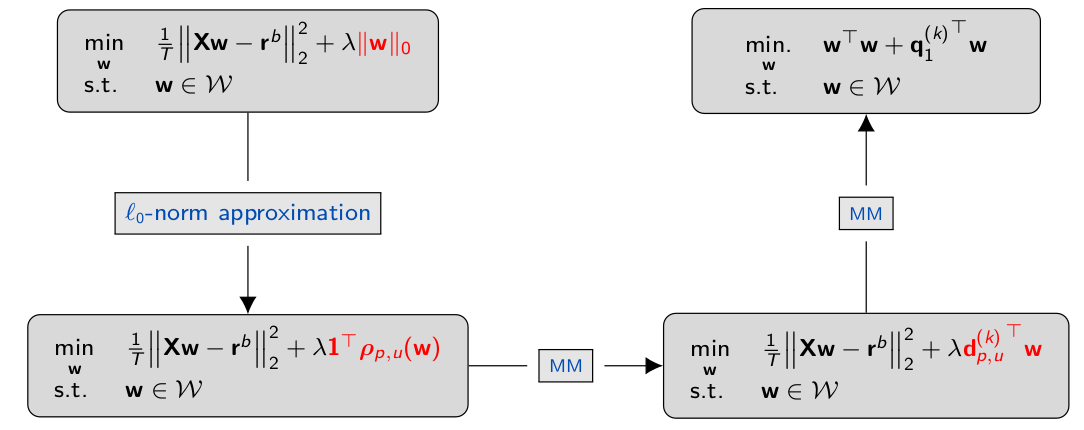
Sparse Index Tracking
SIT的意思是金融上用少数个股票的股价线性加权拟合股指(恒生指数,上证指数等), 主要难点在于这是个一个稀疏问题,我们只能选择其中一部分的股票进行拟合。这个选择过程严谨来说是一个 NP难的问题。
Sparse Regression
lecture中给出了使用MM算法进行求解的方案.
类似于前文,定义对-norm的近似 值越小,则在逼近零的小区间内近似越准,但是在较大的区间内则不太准,因而是一个超参数.且这个函数对是一个凹函数.
新的优化目标函数:
这个函数还不是凸函数,这里采用MM算法进行处理,与前一章一致,使用当前点的切线作为代理函数
在MM中需要迭代多次求解的目标函数:
这个函数是一个QP,仍需要迭代。
对这个QP使用MM,令以及公式
目标函数变为: 其中
对这个问题可以用KKT直接求出最优解. . 会求出
从,得到对的判别条件 从等式约束,得到