Denoising Diffusion Probabilistic Models
这篇paper是diffusion model在生成模型中的应用。这篇文章有一个推导公式比较细致,讲解比较清晰的博客.
Diffusion Model 在生成模型中的特点
该博客中有如此一图,大致总结了当前生成模型的四大类别。对抗网络, VAE, flow-based model, 以及本文的扩散模型。

这几种方式的对比来看,VAE和Flow Model可以快速地采样出种类范围比较广的样本。GAN可以快速采样出质量高的样本,而Diffsion则采样速度慢,但是采样范围种类广且质量很高。
Denoising Diffusion Model 主要工作流与组件分类
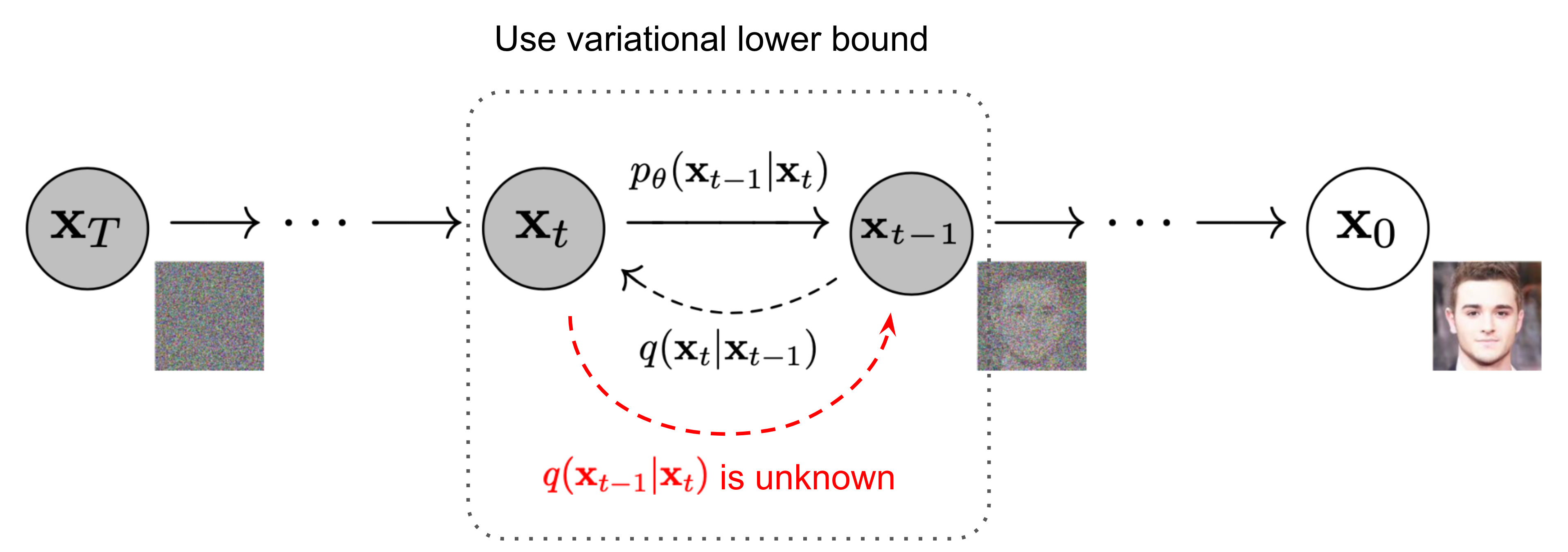 Diffusion 操作上表达的是对图片逐步增加高斯噪声,最终把图片完全corrupt 成噪音的过程,而反向地,从噪音中还原出图片地pattern则是生成的过程。
Diffusion 操作上表达的是对图片逐步增加高斯噪声,最终把图片完全corrupt 成噪音的过程,而反向地,从噪音中还原出图片地pattern则是生成的过程。
数学上来说对图片/数据逐步增加高斯噪声的过程被设计成一个马尔可夫链,每一个时刻的状态只由上一个时刻的均值以及额外的噪声影响。概率地写出公式 , 白话而言就是把前一个时刻的图像/数据/分布scale down, 再与一个额外的高斯分布加和。
反向的时候我们已知,需要逐步估计第步的噪音,然后让数据"减去"这个噪音。本文提出的就是用神经网络,输入和时刻的time_encoding, 估计这个分辨率与原图一样的噪音,并逐步去除噪音得到原图。因而称为"Denoising Diffusion Model".
因而在功能模组上,这类模型分为一下几个部分,不同的文章会有不同的假设以及选择,后面会再数学与代码上给出实例.
- 前向采样,计算从图片到第时刻被corrupt的状态. 这里的主要变量在于采样时间可变,且关于时间的函数,称为noise scheduler是可控制的,如线性增加噪声等方案。
- 噪声估计网络, 输入时刻图片以及time encoding输出同分辨率噪声, 以UNet为主架构,配合Attention等模块选择 (比如后来一些加入语言或外部信息的生成模型多使用attention).
- 损失函数,如何训练噪声估计(图片估计)网络,可以有很强的概率学支撑,也可以像本文最后的baseline implementation一样简单暴力。
- 采样推理,所谓的"减去噪音"步骤,这里可以有更严谨的推导计算得到更准确的数值。
前向采样
如果输入图片也是高斯分布,高斯分布与高斯分布的叠加是闭式的高斯,用递推的公式计算采样的推理过程,可以很快发现我们不需要多步迭代来实现加噪音采样,而是可以根据noise scheduler以及随机数生成器直接得到任意时间点的噪音和图像数据。 令, , 是代码从高斯分布中采样的噪声。
注意两个高斯噪声方差为的的融合,得到的是一个方差为的高斯分布。所以上文的计算实际上是 方差为的高斯分布和的高斯分布的融合,得到的就是方差为的高斯分布,累积结果同样。至此,我们可以根据原数据, 噪声规划器得到的, 以及采样的高斯噪声得到任意时刻的图片
采样推理
作者指出,在已知(conditioned on) 时,反向概率也符合一个高斯分布
由于前向的概率分布是已知的,这里的后验分布就用贝叶斯公式转换为前向 (分子是的乘积概率,更改条件概率的条件 conditioned on , 可将全部变为前向);并重点关注概率分布函数的指数部分, 然后把其中的提出来。 通分并凑平方,找出的方差和均值. 由, 其中
方差 .
把 代入中,
均值 从此可计算出是一个仅与有关的,以为特征的高斯分布。这个均值的计算也可以直观地理解为增强输入数据并减去一个估计的噪声, 就是前向采样的一个逆运算。这个式子也说明了,为什么我们说可以通过估计噪声几乎等价于直接估计
损失函数
直观的设计是说根据前文,计算重建每一个时间的图像,比较反向和正向的图片的相似度作为损失函数,本文则进一步简化这个结果,最终采用的是一个函数,比较预测出来的噪声和实际的噪声的相似性。如果能通过被干扰的图片准确地预测噪声,显然我们就能反推得到原来的输入图片。因而这个损失是直观合理的。
作者进一步从数学角度有分析,思路与VAE很接近。首先明确需要优化问题是, 也就是选择参数, 最大化网络预测的映射函数在数据集数据中概率。
模仿VAE的推理,可以计算得到
从而确定了 的下限(ELBO),注意右项这里是前推函数容易表达,也就是高斯,而是后推条件函数容易表达,也就是网络的预测(噪声).
上文第一项与无关,因为就是噪声,正太高斯分布。最后一项根据的是最后一步的逆推公式做。而中间部分就是两个高斯之间的相似度(KL距离),
高斯之间的相似度严格来说应该如下:
但是可以通过训练噪音或者重建图片的相似性直接绕过这个损失函数的选择。不同点只是在参数的权重上,因而不是重点。但这个推理过程说明了此前简单损失的充分性。